Why Your AI Needs Scalable Verification and Validation
Notes from Mansur Arief's talk on building AI systems worthy of trust
AI systems now diagnose tumors, drive cars, guide aircraft, and manage critical infrastructure. They do all of this remarkably well, until they don’t.
A recent talk by Mansur M. Arief at KFUPM laid out both the urgency and the emerging science of making AI systems trustworthy at scale. This post distills the key ideas.
The Problem Is Real, and It’s Not Going Away
We’ve all seen the amusing failures: AI-generated hands with seven fingers, chatbots confidently stating that two bags of trash per week for a year yields 104 bags on the curb. These are funny in isolation. They stop being funny when the AI is flying an aircraft or controlling a self-driving car on a highway.
 The three core limitations of current AI models.
The three core limitations of current AI models.
The 2025 Stanford AI Index makes a striking observation: across responsible AI benchmarks like BBQ, HarmBench, and Cybench, most popular foundation models have only been evaluated on a handful of safety benchmarks, and no single model dominates across all of them. The safety evaluation landscape is fragmented and incomplete.
Meanwhile, public perception of AI is increasingly optimistic, particularly in the Gulf region. Saudi Arabia ranks among the top four countries globally where people believe AI products bring more benefits than drawbacks. That optimism is a strategic advantage, but it also raises the stakes. If the region is going to lead in AI deployment, it must also lead in making that deployment reliable.
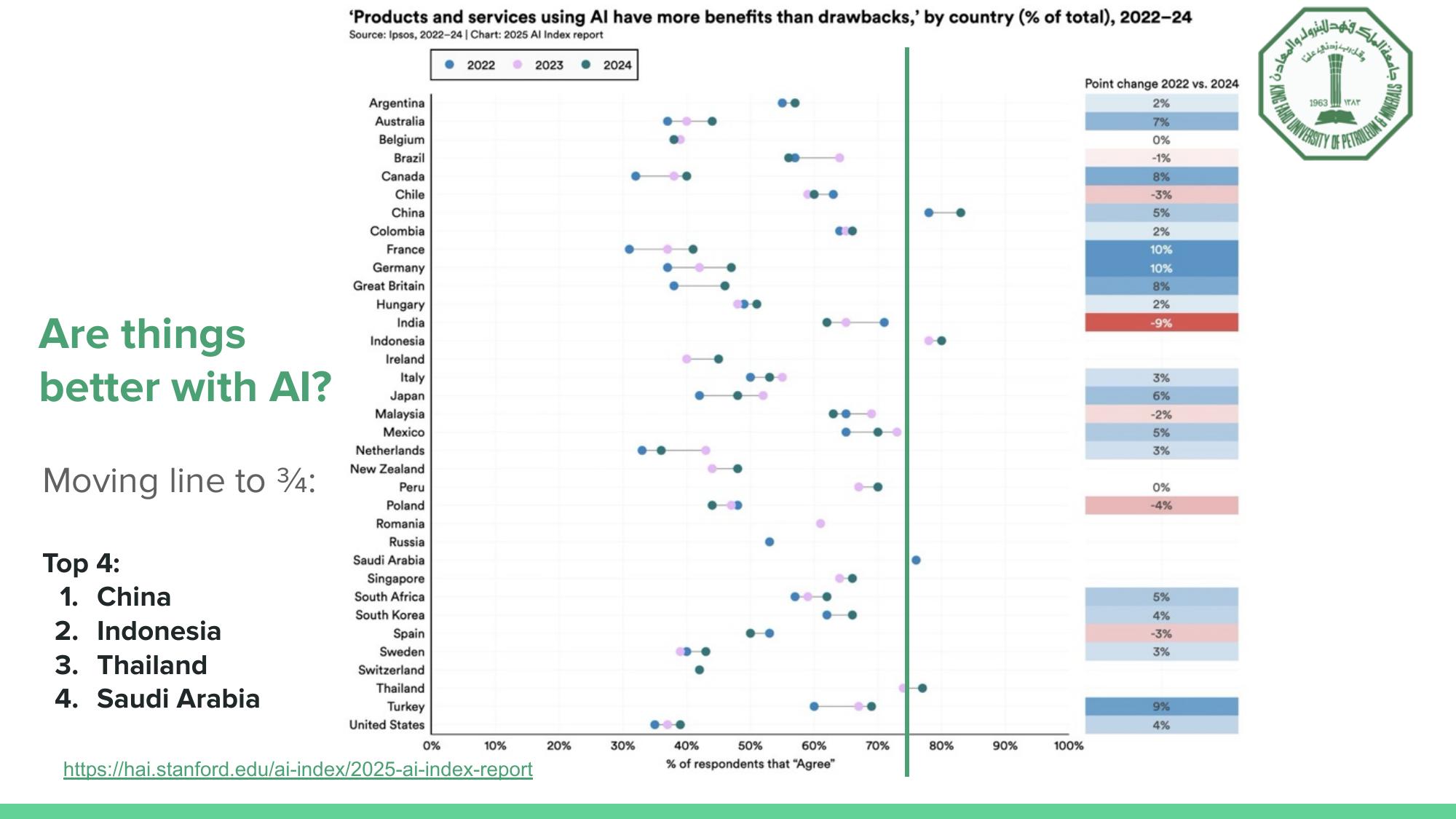 Saudi Arabia is among the top four most AI-optimistic countries globally (Source: 2025 Stanford AI Index).
Saudi Arabia is among the top four most AI-optimistic countries globally (Source: 2025 Stanford AI Index).
Why AI Models Break
At a fundamental level, most AI failures trace back to the same structural problem. A neural network learns a decision boundary from training data. That boundary approximates the true boundary of the real-world phenomenon, but it doesn’t match it perfectly. Near the edges, where the learned boundary diverges from reality, small input perturbations can push a correctly classified sample across the wrong side.
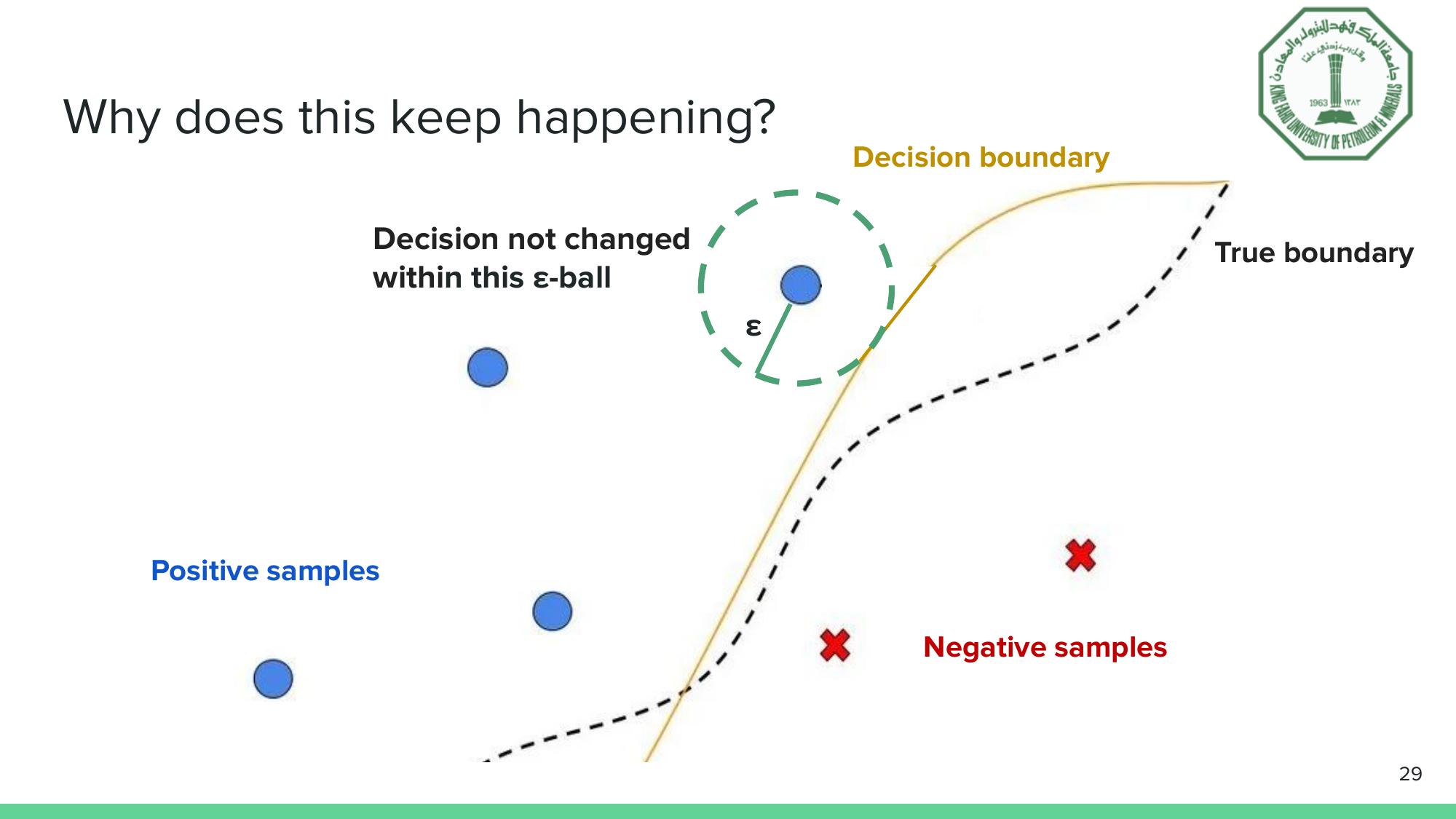 The epsilon-ball concept: if the decision doesn’t change within a small neighborhood around an input, that prediction is locally robust.
The epsilon-ball concept: if the decision doesn’t change within a small neighborhood around an input, that prediction is locally robust.
This is why adversarial attacks work. Crafted noise, invisible to the human eye, can make an object detector miss a traffic light in an image. The perturbation nudges the input across the decision boundary, even though the image looks identical to us. In safety-critical contexts like autonomous driving, this isn’t an academic curiosity. It’s a failure mode that must be formally ruled out.
Verification & Validation is An Old Discipline Meets a New Problem
The engineering world has long relied on Verification and Validation (V&V) to ensure system reliability. Verification asks: are we building the product right?, checking against technical specifications. Validation asks: are we building the right product?, checking against user requirements and real-world needs.
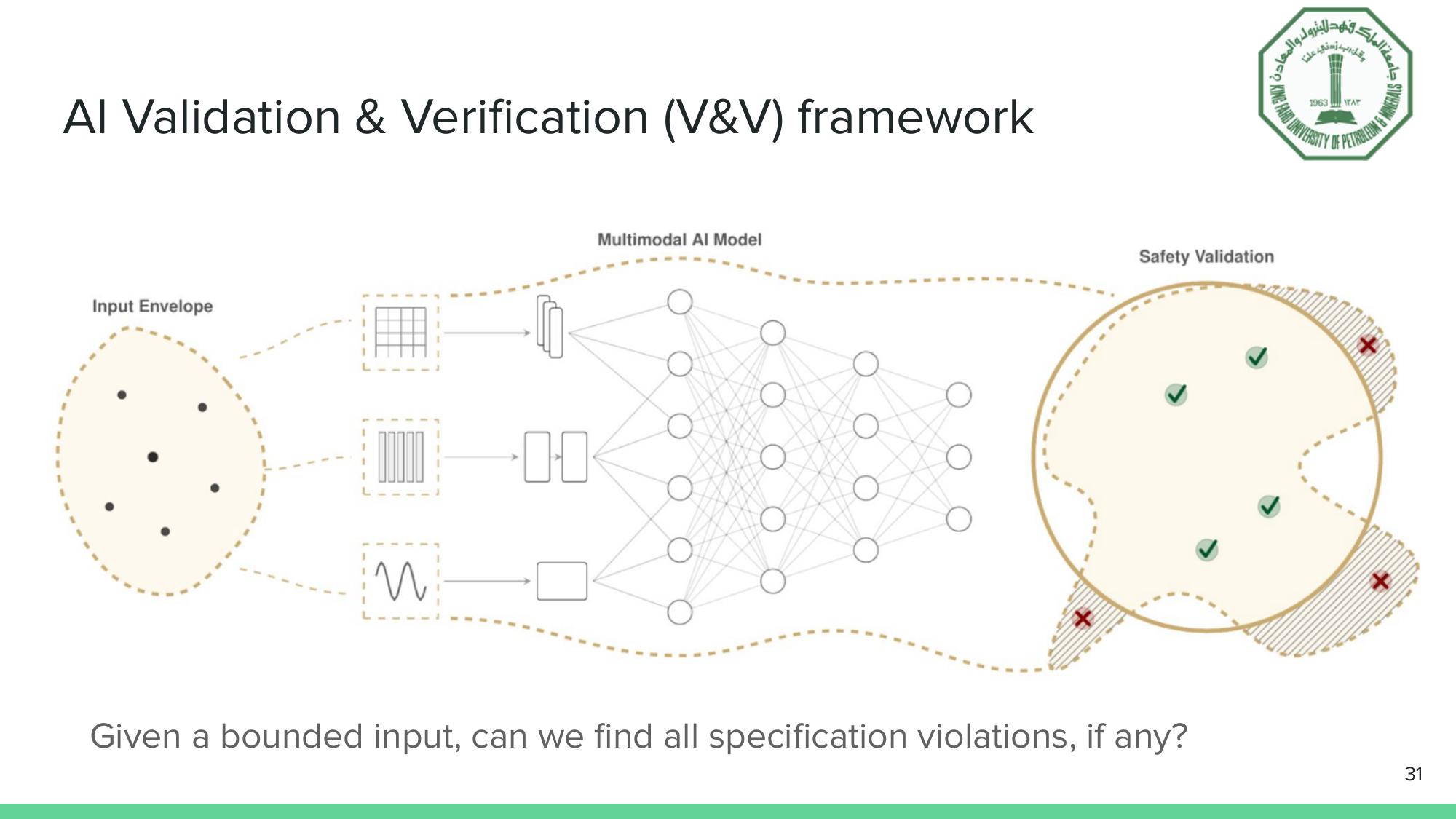 The AI V&V framework: given a bounded input, can we find all specification violations?
The AI V&V framework: given a bounded input, can we find all specification violations?
For traditional software, these questions have well-established answers (think NASA’s V-Model, ISO 26262 for automotive functional safety). But AI systems introduce a complication: the “code” is a learned function with billions of parameters, and the input space is continuous and high-dimensional. You can’t enumerate all test cases. You need mathematical guarantees.
This is where neural network verification enters the picture.
From Simplex to Reluplex
The heart of the talk connects to a foundational verification method we’ve covered in detail in our Reluplex deep dive. The key insight: a neural network with ReLU activations can be encoded as a set of linear constraints plus nonlinear ReLU constraints. The Simplex method handles linear constraints beautifully, but the innocent-looking ReLU function $\max(0, x)$ breaks the entire framework by introducing non-convexity.
Reluplex (Katz et al., 2017) solves this by being lazy about ReLU constraints. Instead of pre-committing to whether each ReLU is active or inactive (which creates $2^n$ subproblems for $n$ ReLUs), Reluplex lets ReLU constraints be temporarily violated and fixes them incrementally. Only when lazy fixing fails does the solver branch, and in practice, the vast majority of ReLUs resolve without branching.
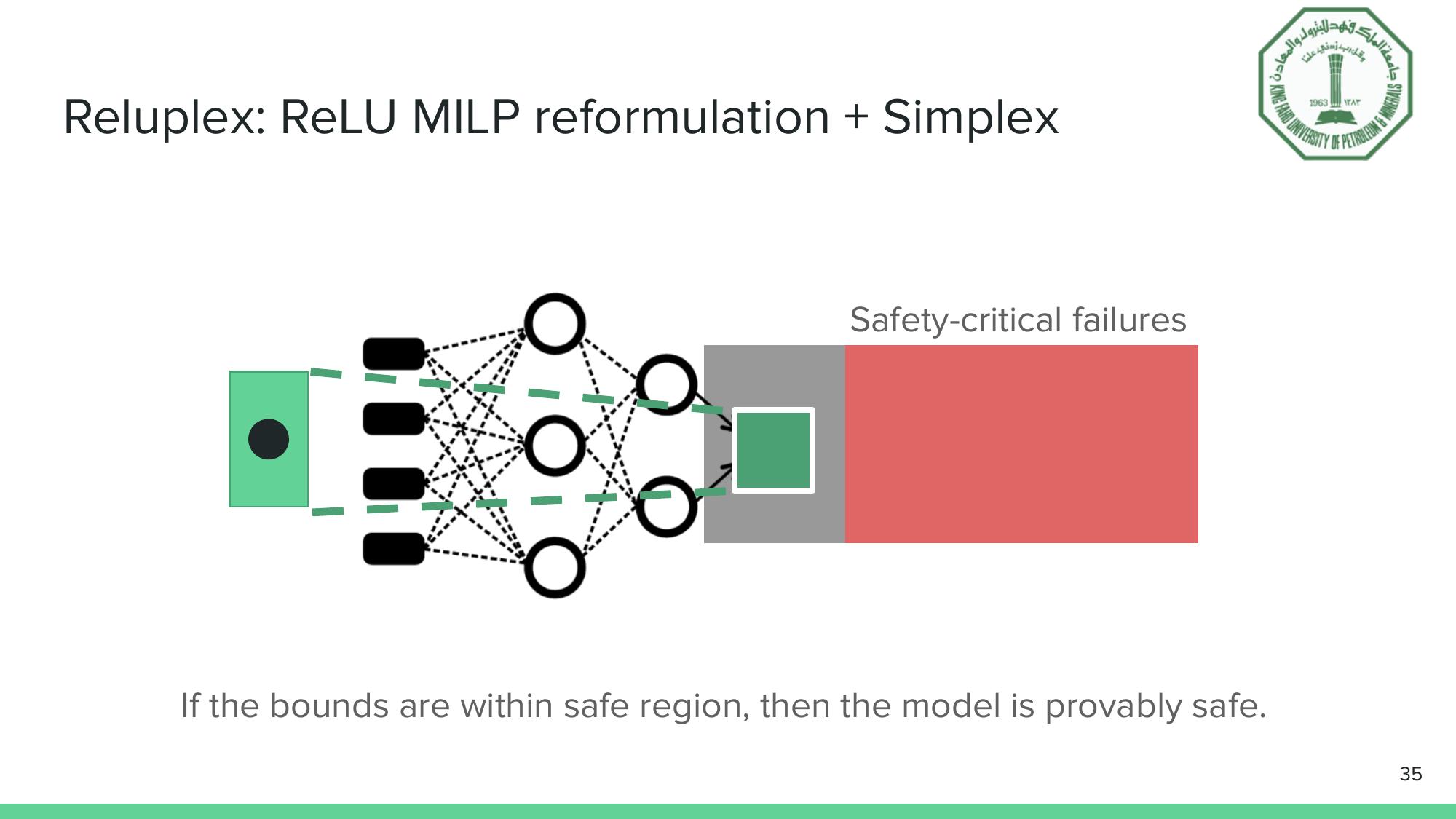 The Reluplex principle: propagate bounds through the network. If the output stays within the safe region, safety is formally guaranteed.
The Reluplex principle: propagate bounds through the network. If the output stays within the safe region, safety is formally guaranteed.
The result: networks with 300 ReLUs, such as those in the ACAS Xu aircraft collision avoidance system, can be verified in minutes to hours, when naive enumeration would take longer than the age of the universe.
Applications Beyond Aircraft
The applications of neural network verification now span well beyond aviation.
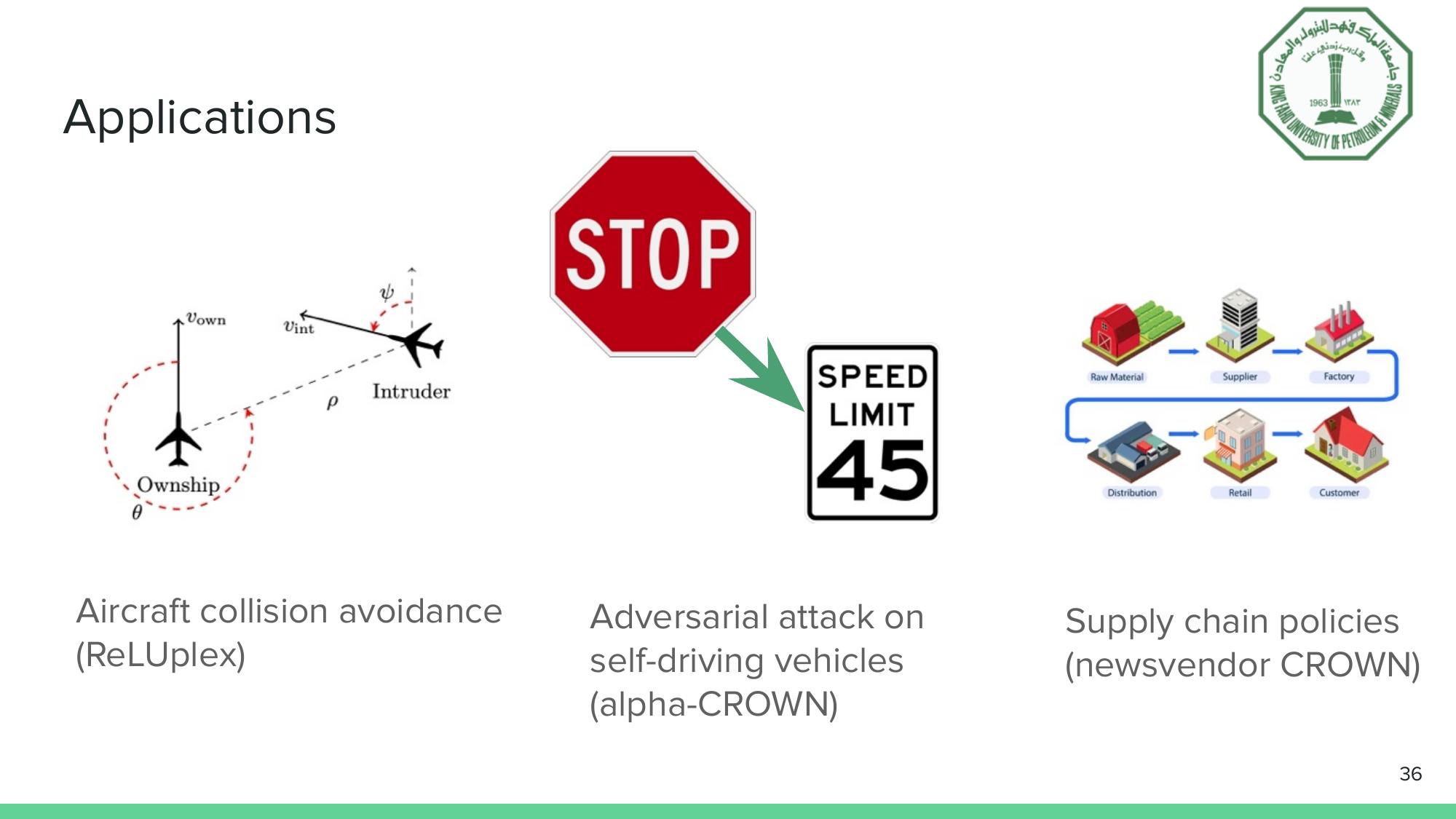 Verification methods applied to aircraft collision avoidance, autonomous vehicle robustness, and supply chain certification.
Verification methods applied to aircraft collision avoidance, autonomous vehicle robustness, and supply chain certification.
Arief’s own research at KFUPM extends verification into a domain you might not expect: supply chain management. Neural network demand forecasters now routinely outperform classical methods, but their high sensitivity to input perturbations means that demand variability can amplify upstream through the supply chain, a phenomenon known as the “bullwhip effect.” His Newsvendor-CROWN framework casts the multi-tier supply chain as a composed piecewise-linear computational graph and applies CROWN-family verification to produce worst-case cost guarantees. The chained verifier is provably tighter than sequential approaches, and the resulting bound widths translate directly into bullwhip ratio measurements, a metric that supply chain managers care about deeply.
Three Research Thrusts for Trustworthy AI
The AI V&V Lab at KFUPM, in collaboration with SDAIA’s Joint Research Center for AI (JRC-AI) and the Interdisciplinary Research Center for Smart Mobility and Logistics (IRC-SML), organizes its research around three thrusts:

1. Theoretical ML verification with practical applications. Moving verification from academic benchmarks to real systems like supply chain certification, aircraft safety, and beyond. The key challenge is scalability: making verification fast enough and tight enough to produce meaningful guarantees on production-scale networks.
2. Applied validation for rare-event robustness. Real-world failures are often rare events like unusual pedestrian behavior or edge-case traffic scenarios. This thrust uses importance sampling and meta-learning to iteratively generate challenging scenarios, train agents against them, and build progressively more robust autonomous systems.
3. Test-time monitoring for world models. Even a verified model can encounter inputs outside its operational design domain during deployment. This thrust develops runtime monitors that flag anomalous situations in real time, triggering fallback strategies before failures occur. The approach combines foundation model embeddings with chain-of-thought reasoning to distinguish inconsequential anomalies from safety-critical ones.
Why This Matters for the Region
Saudi Arabia’s Vision 2030 positions the Kingdom as a leader in technology adoption and AI deployment. The Stanford AI Index shows Saudi Arabia among the world’s most AI-optimistic populations. That enthusiasm, paired with major institutional backing from SDAIA, KFUPM, and the broader research ecosystem, creates a unique opportunity.
But opportunity comes with responsibility. Deploying AI in energy infrastructure, autonomous vehicles, healthcare, and supply chains means deploying it where failures carry real consequences. The V&V framework described here, grounded in mathematical proof rather than empirical testing alone, is how you earn the right to deploy AI in these domains.
As Arief’s talk concluded: we have a great advantage, but we need to develop and deploy reliable AI. The tools to do that are emerging. The question is whether we’ll adopt them as quickly as we adopt the AI systems they’re meant to safeguard.