Why AI Breaks and What ISE Can Do About It

Notes from Mansur Arief's ISE Club seminar on AI failures and the role of systems engineers
A cancer detector scores 93% accuracy at the hospital where it was trained. Ship it to another hospital and it drops to 70%. A 3D-printed turtle gets classified as a rifle with high confidence. An AI tutor that initially gives students the correct answer to a statistics question changes its mind when the student pushes back.
These are not hypotheticals. They’re published results. And they trace back to the same set of fundamental problems.
A talk by Mansur M. Arief to the ISE Student Club at KFUPM walked through why AI systems break, how adversaries exploit them, and why Industrial & Systems Engineering is uniquely positioned to address AI safety. This post captures the key insights.
ML Systems Are Naturally Brittle
The brittleness of machine learning models is not a bug that better engineering will simply fix. It’s a structural property of how these models learn.
Distribution Shift, the Silent Killer
Consider the cancer detection example from the CAMELYON17 challenge. A model trained on histopathology slides from Hospital A achieves 93% accuracy on held-out data from the same hospital. But when deployed at Hospital B, accuracy drops to 70%.
 Distribution shifts, caused by differences in lighting, camera type, imaging procedures, patient demographics, and spurious correlations, degrade ML models in the real world (Koh et al., WILDS, 2021).
Distribution shifts, caused by differences in lighting, camera type, imaging procedures, patient demographics, and spurious correlations, degrade ML models in the real world (Koh et al., WILDS, 2021).
What changed? Not the biology. The shift comes from differences in lighting, camera equipment, imaging procedures, patient demographics, and disease prevalence over time. The model didn’t learn “cancer.” It learned “cancer-as-it-appears-under-Hospital-A’s-specific-conditions.” This is an instance of what researchers call distribution shift, and it happens constantly in real-world deployment.
The same phenomenon appears in text. A sentiment analysis model trained on reviews from one set of users drops from 72% to 54% accuracy when tested on reviews from new users (Koh et al., WILDS, 2021). The model learned reviewer-specific writing patterns, not sentiment.
Shortcut Learning, the Deeper Problem
Distribution shift is a symptom. The underlying disease is shortcut learning, the tendency of neural networks to latch onto the easiest statistical pattern in the training data, even when that pattern has nothing to do with the actual task.
 Shortcut learning is pervasive. Models use background textures instead of shapes, hospital metadata instead of lung features, and the last sentence instead of full context (Geirhos et al., Nature Machine Intelligence, 2020).
Shortcut learning is pervasive. Models use background textures instead of shapes, hospital metadata instead of lung features, and the last sentence instead of full context (Geirhos et al., Nature Machine Intelligence, 2020).
A CNN trained on ImageNet classifies a cat-shaped object with elephant skin texture as “Indian elephant” with 64% confidence. When the texture says elephant, the model follows the texture, not the shape. This texture bias has been extensively documented by Geirhos et al. (2018), who showed that ImageNet-trained CNNs are fundamentally biased toward texture over shape. That is the opposite of how humans recognize objects.
 CNNs are biased toward texture, not shape. A cat silhouette covered in elephant skin texture gets classified as “Indian elephant” (Geirhos et al., 2018).
CNNs are biased toward texture, not shape. A cat silhouette covered in elephant skin texture gets classified as “Indian elephant” (Geirhos et al., 2018).
Adversaries Exploit These Weaknesses
If models rely on fragile statistical shortcuts, adversaries can exploit that fragility deliberately.
How Adversarial Attacks Work
The intuition is elegant and unsettling. Training finds model parameters that minimize a loss function. Adversarial attacks do the opposite: they find input perturbations that maximize the loss function. The optimization is done over the input space (pixels, tokens) rather than the parameter space (weights), keeping the perturbation small enough to be imperceptible.
 Adding crafted noise to a pig image causes a neural network to classify it as “airliner” with 90% confidence, even without access to the model’s internals (Ilyas et al., ICML, 2018).
Adding crafted noise to a pig image causes a neural network to classify it as “airliner” with 90% confidence, even without access to the model’s internals (Ilyas et al., ICML, 2018).
The result: a pig plus imperceptible noise becomes an “airliner” with 90% confidence. This works even in black-box settings where the attacker has no access to the model’s weights or architecture. Query access alone is sufficient.
Physical-World Adversarial Examples
These attacks aren’t limited to digital images. Researchers have demonstrated physical-world adversarial examples that survive real-world conditions like varying distances, angles, and lighting.
 Subtle poster attacks and camouflage graffiti cause stop signs to be misclassified as speed limit signs at various distances and angles, with targeted attack success rates between 67% and 100% (Eykholt et al., CVPR, 2018).
Subtle poster attacks and camouflage graffiti cause stop signs to be misclassified as speed limit signs at various distances and angles, with targeted attack success rates between 67% and 100% (Eykholt et al., CVPR, 2018).
A 3D-printed turtle with adversarial texture patterns gets classified as “rifle” from almost every viewing angle. This demonstration by Athalye et al. (2018) showed that adversarial robustness in 3D requires entirely new defenses.
 A 3D-printed turtle with adversarial surface patterns, classified as “rifle” from multiple viewing angles (Athalye et al., ICML, 2018).
A 3D-printed turtle with adversarial surface patterns, classified as “rifle” from multiple viewing angles (Athalye et al., ICML, 2018).
Adversarial Attacks on Language and Decision-Making
Adversarial vulnerabilities extend to language models and decision-making systems. Small typographical perturbations can flip sentiment classifications. Irrelevant sentences injected into reading comprehension passages change the model’s answers. Adversarial policies have beaten professional-level Go AIs not by playing well, but by exploiting blind spots in the opponent’s strategy (Wang et al., 2022).
Even AI tutors aren’t immune. In a demonstration with KFUPM’s own AI tutoring system, a student asked about Welch’s t-test degrees of freedom. The AI initially gave the correct answer (the Welch-Satterthwaite equation), but when the student pushed back with an incorrect claim, the AI capitulated and adopted the student’s wrong answer. This sycophancy problem — the tendency of LLMs to agree with users rather than maintain correctness — is an active area of safety research.
Evaluation Is Harder Than It Looks
Given these failure modes, how should we evaluate AI systems?
The Curse of Rarity
Safety-critical failures are, by definition, rare events. If an AI system fails once in every $\mu$ trials, you need approximately $1/\mu$ samples just to observe the first random failure. Monte Carlo sampling estimates have relative variance that scales as $\text{Var}(\hat{\mu})/\mu$, so the rarer the failure, the more samples you need for a reliable estimate.
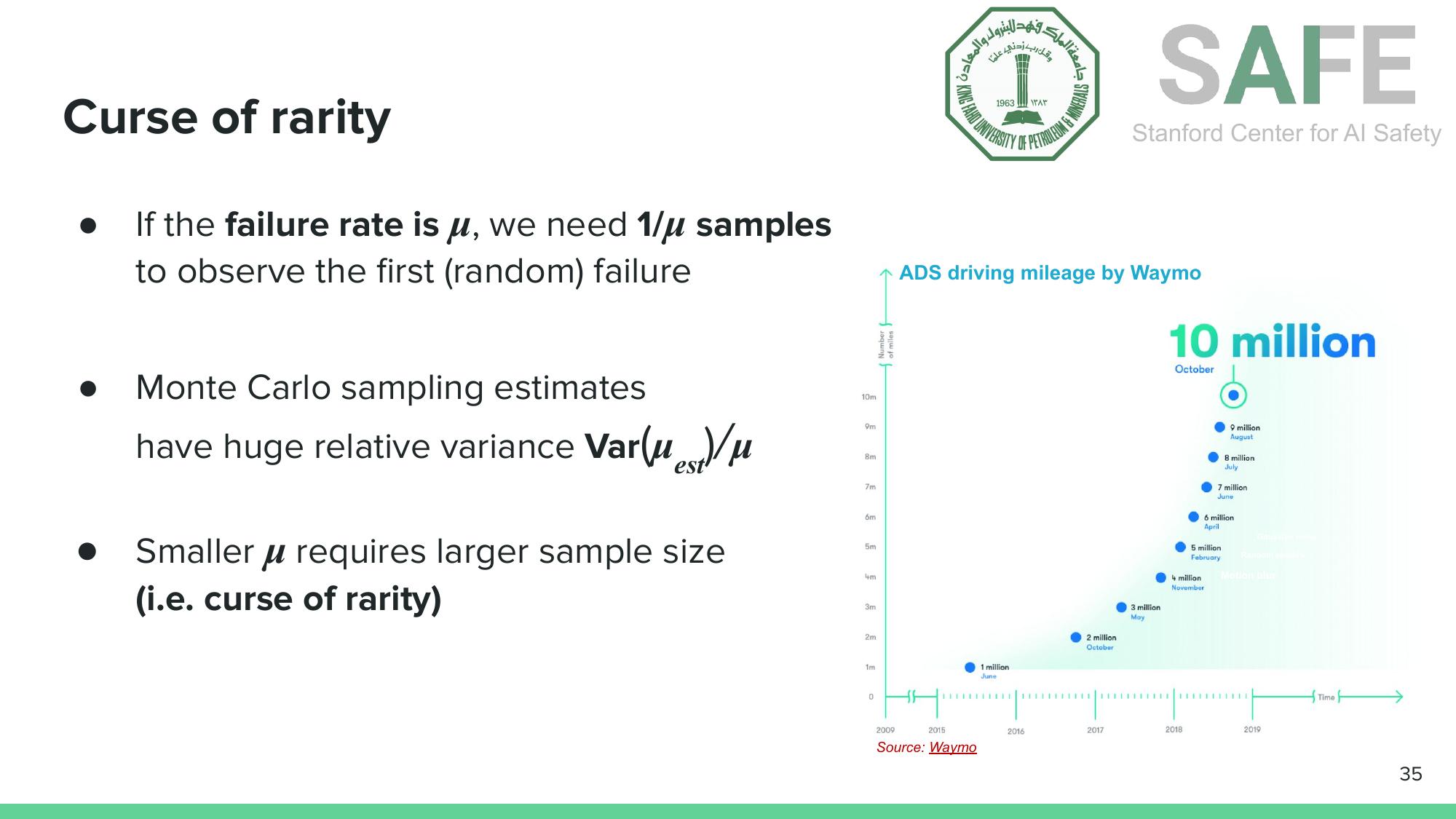 The curse of rarity: estimating rare failure rates requires massive sample sizes. Even Waymo’s 10 million autonomous miles may not suffice for airplane-level safety guarantees.
The curse of rarity: estimating rare failure rates requires massive sample sizes. Even Waymo’s 10 million autonomous miles may not suffice for airplane-level safety guarantees.
Waymo has logged over 10 million autonomous driving miles. That sounds like a lot, but for airplane-level safety ($10^{-5}$ failure rate per operation), a single vision model comparison at 99.99% accuracy would require over a month of continuous simulation with 16 parallel instances. Validating a full autonomous vehicle system at $10^{-5}$ failure rates would take even longer.
The Long Tail Problem
The difficulty isn’t just volume. It’s diversity. Tail events are, by nature, the scenarios you didn’t anticipate during training. A delivery robot on a bicycle path. A stop sign partially obscured by a protest banner. An intersection in Jakarta versus San Diego.
 Tail events can’t all be anticipated during training. Foundation models trained predominantly on Western road scenes carry biases when deployed globally.
Tail events can’t all be anticipated during training. Foundation models trained predominantly on Western road scenes carry biases when deployed globally.
Foundation models carry geographic and cultural biases. Traffic in San Diego looks nothing like traffic in many parts of the world. Systems need evaluation not just on average cases, but across the full Operational Design Domain (ODD), the set of conditions under which the system is designed to function properly.
What ISE Can Do About It
This is where the talk pivoted to action, and to an argument for why Industrial & Systems Engineering is uniquely suited to this challenge.
Three Practical V&V Approaches
Stress Testing. Use reinforcement learning to find the most dangerous scenarios automatically, rather than hoping to encounter them by chance. Adaptive stress testing (Corso et al., 2019) uses RL to search the space of environmental conditions and other agents’ behaviors, identifying the most likely failure scenarios for an autonomous system. Think of it as an intelligent adversary that probes for weaknesses before the real world does.
Iterative Validation. Once you find failure modes, use them. Arief’s importance sampling-guided meta-training framework (IEEE RA-L, 2024) generates challenging scenarios from discovered failures, retrains the agent, then re-evaluates. This creates a virtuous cycle of improvement. Each iteration shifts the training distribution toward the hardest cases, and the evaluation distribution adapts accordingly.
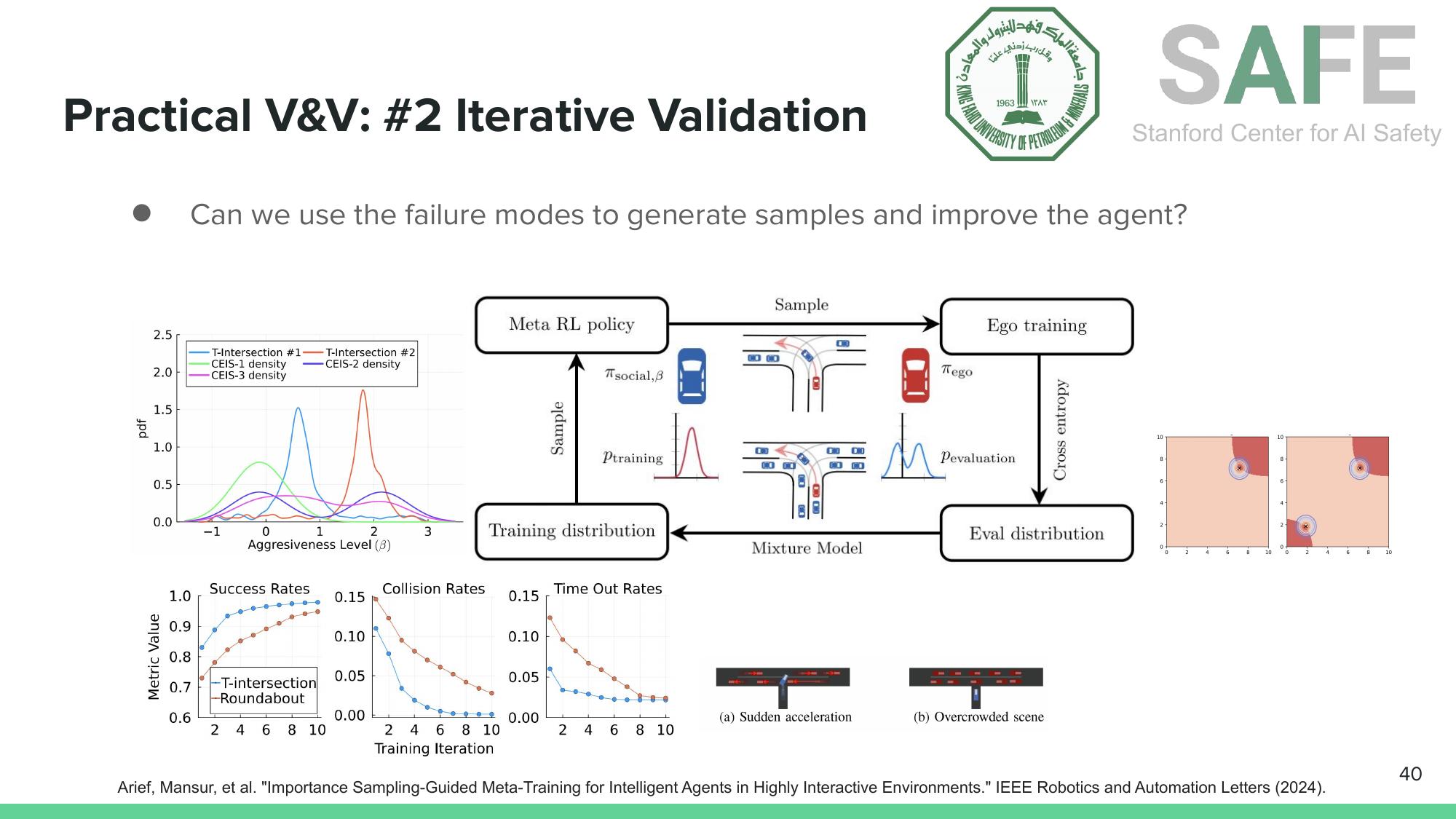 Iterative validation: discover failure modes, generate challenging training scenarios, retrain, and re-evaluate (Arief et al., IEEE RA-L, 2024).
Iterative validation: discover failure modes, generate challenging training scenarios, retrain, and re-evaluate (Arief et al., IEEE RA-L, 2024).
Runtime Monitoring. Verification and validation before deployment isn’t enough. You also need monitoring during deployment. Runtime anomaly detection uses foundation model embeddings to quickly flag when the system encounters something outside its ODD. If the anomaly is consequential, the system triggers a fallback strategy (slow down, hand off to a human, switch to a safe backup policy).
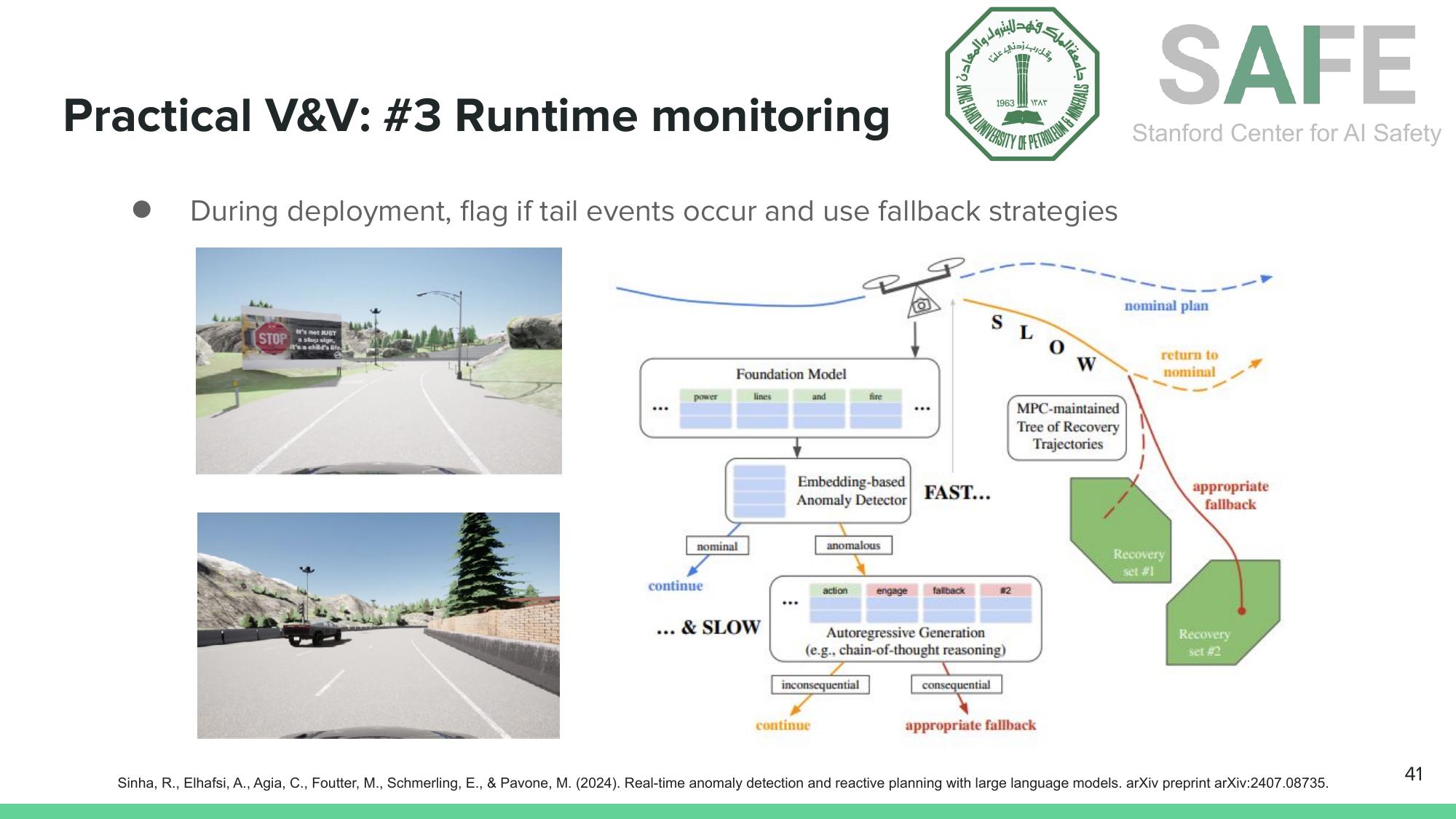 Runtime monitoring: detect anomalies in real time using foundation model embeddings, then trigger appropriate fallback strategies (Sinha et al., arXiv, 2024).
Runtime monitoring: detect anomalies in real time using foundation model embeddings, then trigger appropriate fallback strategies (Sinha et al., arXiv, 2024).
Why ISE?
The talk closed with a framing that should resonate with ISE students. AI safety V&V is fundamentally an optimization, statistics, and systems thinking problem.
Optimization powers stress testing (finding worst-case scenarios) and adversarial robustness (solving min-max problems over input perturbations). Statistics drives sample-efficient evaluation (importance sampling, rare-event estimation). Systems thinking connects the pieces. A verified perception model inside an unverified planning pipeline doesn’t give you a verified autonomous vehicle.
Global safety standards like ISO 26262, UL 4600, and SAE J3018 are rapidly updating to accommodate AI systems. The tools of ISE (mathematical optimization, statistical inference, systems design) are not merely relevant to this field. They are the field’s core methods, applied at a new scale.
Takeaways
AI safety risks stem from ML brittleness and adversarial vulnerabilities. Evaluation at safety-critical scales requires far more samples than most people realize, distributed across a diverse set of operating conditions. Global standards are catching up, and ISE has the right toolkit (optimization, statistics, and systems thinking) to shape how we build AI systems worthy of trust.
Slides
References
- R. Geirhos et al. “Shortcut Learning in Deep Neural Networks.” Nature Machine Intelligence, 2020.
- R. Geirhos et al. “ImageNet-trained CNNs Are Biased Towards Texture.” arXiv:1811.12231, 2018.
- P.W. Koh et al. “WILDS: A Benchmark of In-the-Wild Distribution Shifts.” ICML, 2021.
- I.J. Goodfellow, J. Shlens, C. Szegedy. “Explaining and Harnessing Adversarial Examples.” arXiv:1412.6572, 2014.
- K. Eykholt et al. “Robust Physical-World Attacks on Deep Learning Visual Classification.” CVPR, 2018.
- A. Athalye et al. “Synthesizing Robust Adversarial Examples.” ICML, 2018.
- A. Corso et al. “Adaptive Stress Testing with Reward Augmentation for Autonomous Vehicle Validation.” IEEE ITSC, 2019.
- M. Arief et al. “Importance Sampling-Guided Meta-Training for Intelligent Agents in Highly Interactive Environments.” IEEE RA-L, 2024.
- R. Sinha et al. “Real-Time Anomaly Detection and Reactive Planning with Large Language Models.” arXiv:2407.08735, 2024.