What Systems Engineers Know That AI Developers Are Slowly Learning

Our lab recently spent time with the NASA Systems Engineering Handbook, a 360-page document that gets revised after every major mission failure. The handbook is dense, bureaucratic in places, and full of diagrams that look like they were made in PowerPoint 2003, but it’s also one of the most useful things we’ve read for thinking about AI safety.
The handbook covers how to build spacecraft, satellites, and ground systems that have to work the first time with no second chances. When the Mars Climate Orbiter burned up because one team used metric units and another used imperial, engineers revised the handbook. When Columbia disintegrated on reentry because foam strikes were deemed acceptable, they revised it again. Each catastrophe left its mark in the form of new processes, new checklists, new ways of catching errors before they become fatal.
Two chapters caught our attention: Chapter 4 on System Design, and Chapters 5.3 and 5.4 on Product Verification and Validation. Together they describe a discipline that AI practitioners would do well to study.
The V&V distinction that keeps getting lost
NASA separates verification from validation with what seems like a simple question. Verification asks whether we built the product right, while validation asks whether we built the right product.
The difference matters more than it sounds. You can verify that a neural network achieves 94% accuracy on the test set, that the gradients converge, that the architecture matches the specification, and all of that can be true while the system fails completely in deployment because the test set didn’t represent the operational environment.
The handbook puts it bluntly:
Many systems successfully complete verification but then are unsuccessful in some critical phase of the validation process, delaying development and causing extensive rework and possible compromises with the stakeholder.
This describes most AI deployment failures. The model verified against benchmarks, but the validation against real operational conditions either never happened, happened too late, or happened in ways that didn’t surface the actual failure modes.
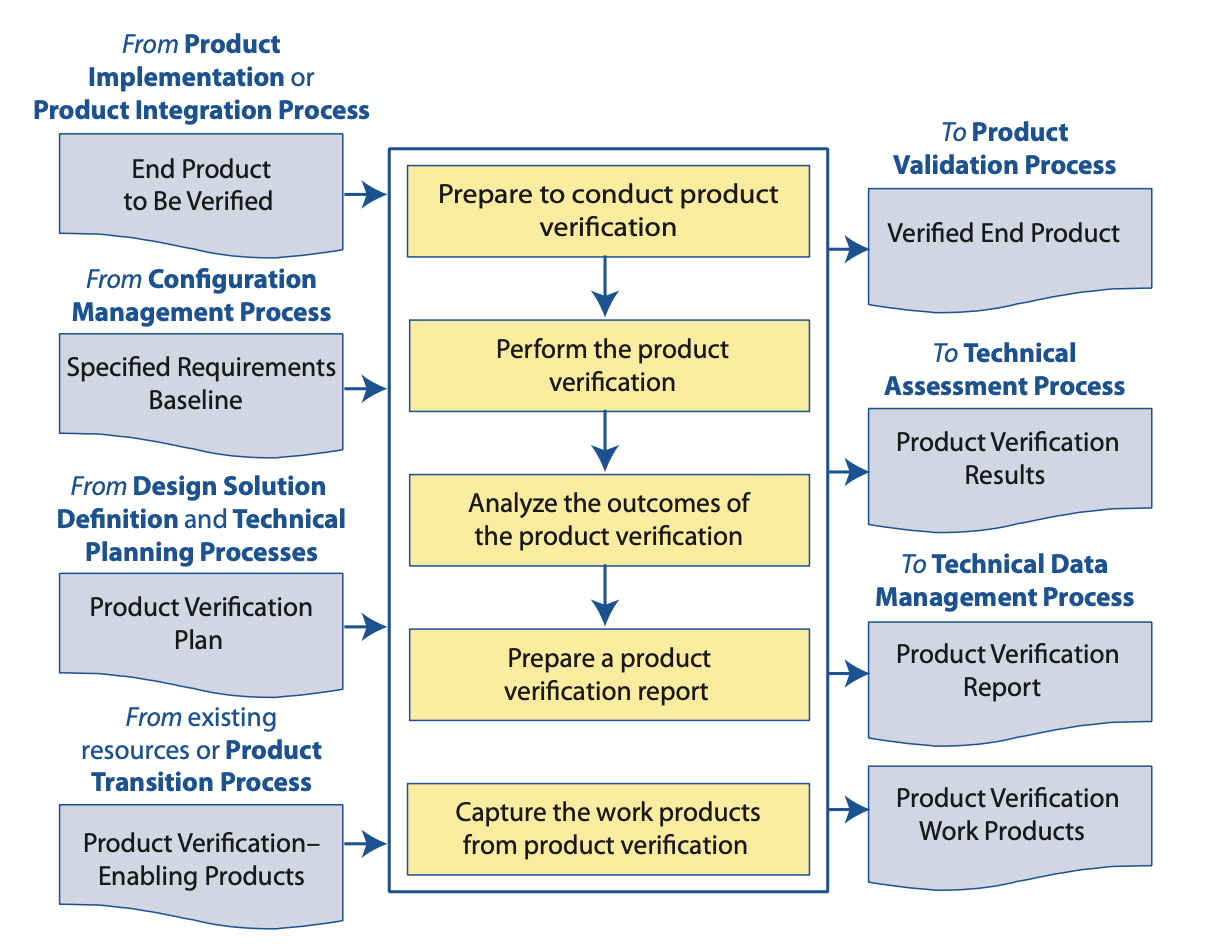 Figure 5.3-1 from the NASA Systems Engineering Handbook. The verification process flows from specified requirements through preparation, conduct, analysis, and capture of work products, with each arrow representing a control point where failures can be caught.
Figure 5.3-1 from the NASA Systems Engineering Handbook. The verification process flows from specified requirements through preparation, conduct, analysis, and capture of work products, with each arrow representing a control point where failures can be caught.
Stakeholder expectations before architecture
NASA’s system design process doesn’t start with architecture or technology selection but with stakeholder expectations. Who uses this system? What do they actually need? Under what conditions will it operate? What counts as success, and what counts as failure?
This information gets documented in something called the Concept of Operations, or ConOps, which describes how the system will operate during every phase of its lifecycle from integration and test through launch, operations, and disposal. The ConOps forces engineers to think through scenarios before writing code or bending metal.
The handbook specifies what belongs in a ConOps: major operational phases, operation timelines, operational scenarios, end-to-end communications, command and data architecture, logistics, and critical events. For human spaceflight missions, functions must be explicitly allocated between human operators and automated systems.
Compare this to how most AI systems get developed. Someone trains a model to optimize a metric, the “stakeholders” are imagined rather than consulted, the deployment environment is assumed rather than characterized, and the operational scenarios exist only as test cases rather than descriptions of actual use. The ConOps, if it exists at all, gets written after deployment when things start breaking.
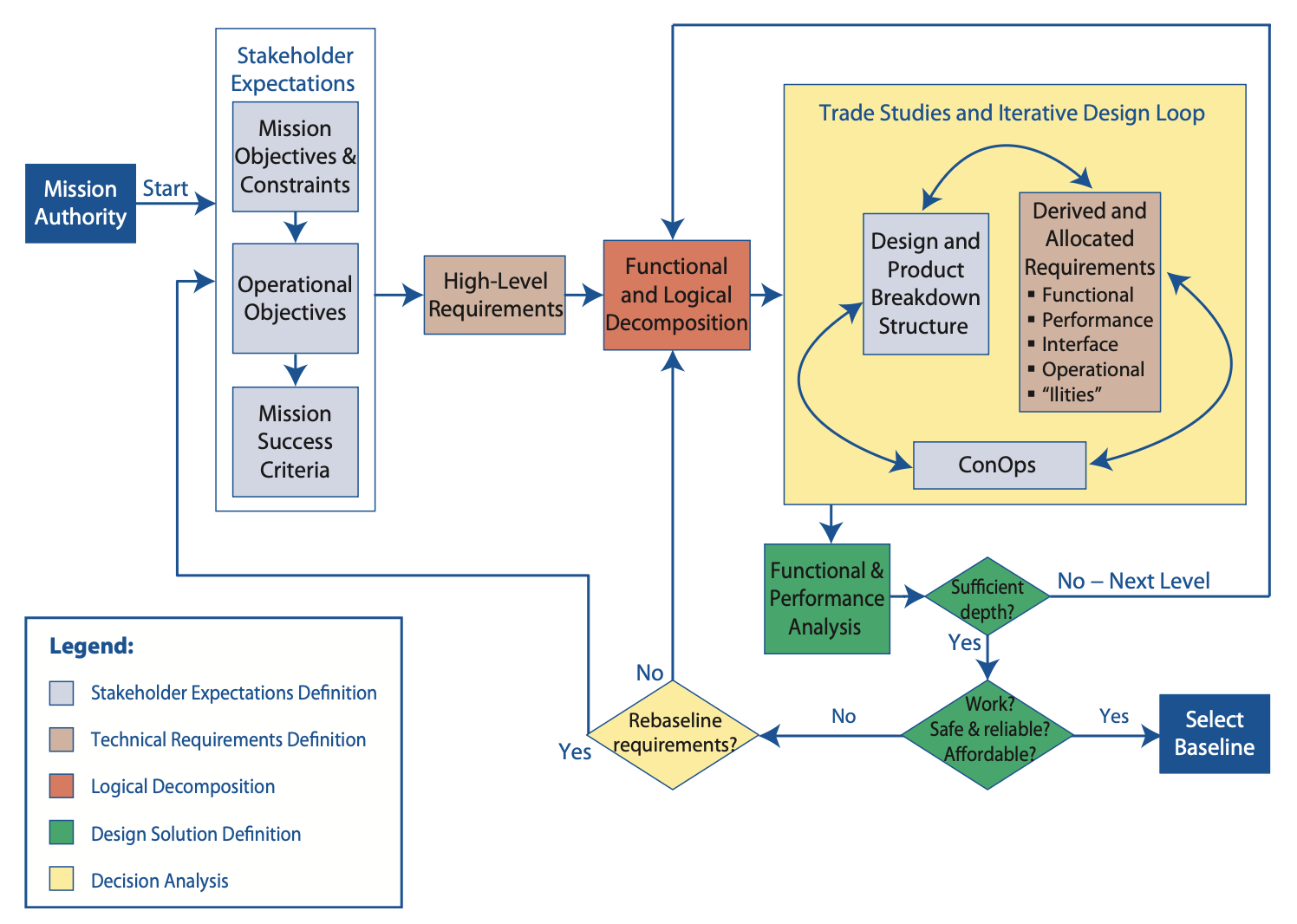 Figure 4.0-1 from the NASA Systems Engineering Handbook. The recursive relationship among system design processes, where stakeholder expectations feed technical requirements, which inform decomposition, which guides design. Trade studies validate each layer against the ones above.
Figure 4.0-1 from the NASA Systems Engineering Handbook. The recursive relationship among system design processes, where stakeholder expectations feed technical requirements, which inform decomposition, which guides design. Trade studies validate each layer against the ones above.
Four verification methods, not just testing
NASA recognizes four distinct verification methods, each with different strengths.
Test subjects the actual product to controlled stimuli and measures the response. For spacecraft this means thermal vacuum chambers, vibration tables, and acoustic environments; for AI this corresponds to evaluation on held-out data, adversarial examples, and edge cases.
Analysis uses mathematical models to predict performance and is useful when testing is impractical or prohibitively expensive. For AI this maps to formal verification methods, interpretability techniques, and certified bounds on behavior. At the AI V&V Lab we work extensively with CROWN-family bound propagation for this purpose.
Inspection examines the product to verify conformance to documentation and catch manufacturing defects. For AI this corresponds to code review, architecture review, and data pipeline audits.
Demonstration shows that the product performs required functions without measuring specific parameters. For AI this maps to human-in-the-loop trials, user studies, and operational pilots.
The insight is that no single method suffices. A comprehensive verification program combines all four, with the mix varying by component, requirement, and lifecycle phase. A safety-critical subsystem might require formal analysis, extensive testing, independent inspection, and operational demonstration before deployment. Most AI development relies almost entirely on testing with occasional inspection via code review, while analysis in the formal sense remains rare and demonstration happens only when users complain.
End-to-end testing and operational scenarios
One of NASA’s core verification practices is end-to-end testing, which the handbook calls “probably the most significant element of any project verification program” while insisting on a principle: test the way you fly.
This means assembling the system in its realistic configuration, subjecting it to realistic conditions, and exercising all expected operational modes. For scientific missions this includes realistic inputs to instruments with data flowing through the entire processing pipeline, and the test environment should approximate operational conditions with any differences documented.
The handbook lists what end-to-end testing must cover: mission phase transitions, first-time events, performance limits, fault protection routines, failure detection and recovery logic, safety properties, responses to off-nominal signals, and communication links.
For AI systems the equivalent would be staging environments that realistically simulate production, covering the entire pipeline from data ingestion through inference, postprocessing, and integration with downstream systems. User feedback loops should be tested, monitoring and alerting should be validated, and degradation scenarios should be exercised.
The handbook also recommends that “an operations staff member who has not previously been involved in testing activities” should exercise the system, since fresh eyes catch assumptions that developers have internalized. For AI this argues for red teams, external audits, and adversarial evaluation by parties not invested in the system’s success.
Traceability as survival infrastructure
NASA requires that requirements trace upward to their origins and downward to their implementations. At every level of the system hierarchy you can ask where a requirement came from, what design decisions satisfy it, and what tests verify it.
This isn’t bureaucratic overhead but survival infrastructure. When a failure occurs, traceability allows engineers to determine which requirement was violated, which design decision contributed, and which tests should have caught the problem. When requirements change, traceability identifies all affected components.
For AI systems this discipline would require something many organizations lack: a clear mapping from model behavior to business requirements to stakeholder needs. When the model is wrong, can you trace the error to a specific capability gap? When stakeholder needs evolve, can you identify which components require retraining? When you improve a subsystem, can you predict the impact on overall system behavior?
The distribution shift problem that plagues deployed AI systems is partly a traceability problem. The original training data represented certain conditions, those conditions changed, but without explicit traceability between operational requirements and training data characteristics the mismatch wasn’t detected until the system failed.
What this means for AI in the Gulf
Saudi Arabia’s Vision 2030 includes substantial investment in AI across transportation, energy, healthcare, and government services, and the National Strategy for Data and AI sets ambitious targets. Autonomous vehicles are already in pilot operation at Riyadh airport and educational districts, with regulations entering force this year.
These are systems that cannot afford to fail. When AI makes decisions about insulin dosing, collision avoidance, or flight control, the standards for trustworthiness change fundamentally.
NASA’s discipline emerged from sixty years of building systems where failure was catastrophic. The verification and validation frameworks, stakeholder processes, traceability requirements, and end-to-end testing practices they developed aren’t academic exercises but accumulated wisdom from an organization that sends machines to places humans cannot reach.
The invitation for AI practitioners is to read NASA’s handbook not as an aerospace document but as a guide to building systems that deserve trust. The specific techniques will differ since neural networks are not rocket engines, but the underlying philosophy transfers: understand what stakeholders need, decompose requirements to verifiable components, verify each component against specifications, validate the integrated system against operational reality, and monitor continuously through deployment.
At the AI V&V Lab at KFUPM we’re working on adapting these principles to modern machine learning systems, including formal verification methods that can certify network behavior, operational domain characterization that borrows from the ConOps tradition, and runtime monitoring that enables continuous validation rather than one-time certification.
The gap between “works on benchmarks” and “trustworthy in deployment” is real, and NASA has been closing that gap for decades. The lessons are there for those willing to learn them.
References
NASA Systems Engineering Handbook, NASA/SP-2007-6105 Rev1, December 2007. Available at ntrs.nasa.gov.
DO-178C: Software Considerations in Airborne Systems and Equipment Certification, RTCA SC-205 / EUROCAE WG-71, 2011. The aviation industry’s standard for software assurance.
IEC 61508: Functional Safety of Electrical/Electronic/Programmable Electronic Safety-related Systems, International Electrotechnical Commission. The foundational standard for functional safety.
ISO 26262: Road Vehicles – Functional Safety, International Organization for Standardization. Adaptation of IEC 61508 for automotive systems.
EASA Concept Paper on AI in Aviation, European Union Aviation Safety Agency, First Issue 2024. Emerging guidance on AI certification in safety-critical aviation.
Stanford AI Index Report 2024, Stanford University Human-Centered AI Institute. Annual assessment of AI progress across sectors.