Operationalizing NASA's Product Verification Process in a Jupyter Notebook

In our previous post on NASA’s Systems Engineering Handbook, we walked through the conceptual framework that spacecraft engineers use to verify and validate complex systems. The four verification methods, the traceability requirements, the stakeholder-first design philosophy. All of it grounded in sixty years of building machines that work millions of miles from help.
This post is the hands-on companion. We take the Product Verification Process from Chapter 5.3 of the NASA Systems Engineering Handbook and operationalize it in a Jupyter notebook, with a concrete AI system as our subject: a small neural network that predicts robot trajectories from sensor input and issues control commands.
The focus here is not on the ML algorithms. The neural network is deliberately simple. What matters is the surrounding infrastructure of requirements, traceability, verification methods, and structured reporting that NASA’s process demands. The notebook itself becomes the verification artifact.
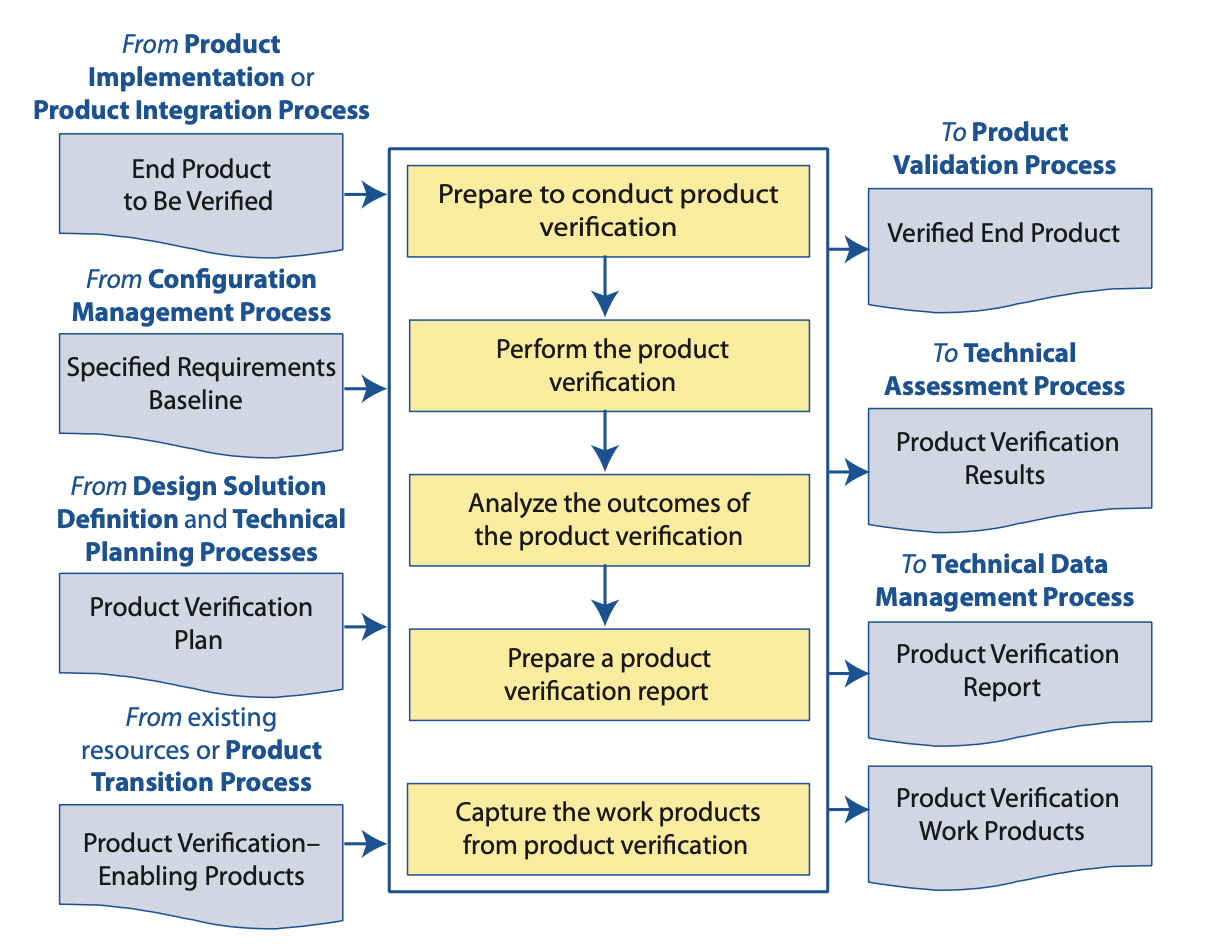 Figure 5.3-1 from the NASA Systems Engineering Handbook. The five activities in the center column, along with their inputs from the left and outputs to the right, form the verification process we operationalize below.
Figure 5.3-1 from the NASA Systems Engineering Handbook. The five activities in the center column, along with their inputs from the left and outputs to the right, form the verification process we operationalize below.
The system under verification
We need something concrete to verify. Our system is a feedforward neural network that takes sensor readings from a simulated 2D robot (position, velocity, heading, and distance to the nearest obstacle) and predicts the trajectory for the next five timesteps, plus a control command (turn left, go straight, turn right).
This is intentionally modest. A two-layer network with ReLU activations, trained on synthetic data from a simple kinematic simulator. You can build and train it in under fifty lines of PyTorch. The entire notebook runs in a few minutes on a laptop.
The point is that even this toy system benefits enormously from structured verification. If NASA’s process applies here, imagine what it reveals for the real systems being deployed in autonomous vehicles on Saudi roads or in drone delivery corridors being planned across the Gulf.
Reading the flowchart as a recipe
Look at Figure 5.3-1 again. The five yellow boxes in the center column describe the verification activities:
- Prepare to conduct product verification
- Perform the product verification
- Analyze the outcomes of the product verification
- Prepare a product verification report
- Capture the work products from product verification
The inputs come from the left: the end product to be verified (our trained neural network), the specified requirements baseline (performance and safety requirements we define), the product verification plan (which methods we’ll use for each requirement), and any verification-enabling products from existing resources (test data, simulation tools, helper functions).
The outputs flow to the right: a verified end product, verification results for technical assessment, a verification report, and archived work products for data management.
Most AI practitioners do some version of activity two (run some tests) and skip everything else. The NASA process insists that preparation, analysis, reporting, and archival are equally important. We will implement all five.
Activity 1, Preparation
NASA’s preparation step requires assembling the inputs before any testing begins. In our notebook, this means defining three things explicitly: the requirements baseline, the verification plan, and the enabling products.
The requirements baseline
Requirements need to be specific, measurable, and traceable. “The model should work well” is not a requirement. Here is what a proper baseline looks like for our trajectory predictor:
requirements = {
"REQ-PRED-01": {
"text": "Predicted trajectory shall have mean squared error below 0.05 "
"over the test set for each of the 5 predicted timesteps.",
"category": "performance",
"verification_method": "test",
"traces_to": "STKH-01: Robot must follow planned path within 0.5m tolerance"
},
"REQ-PRED-02": {
"text": "Control command accuracy shall exceed 92% on the test set.",
"category": "performance",
"verification_method": "test",
"traces_to": "STKH-02: Robot must select correct avoidance maneuver"
},
"REQ-SAFE-01": {
"text": "For any input where obstacle distance is below 0.3 (normalized), "
"the model shall never output 'go straight' when the obstacle "
"is within 15 degrees of the heading.",
"category": "safety",
"verification_method": "analysis",
"traces_to": "STKH-03: Robot must not collide with detected obstacles"
},
"REQ-SAFE-02": {
"text": "Model predictions shall remain stable under input perturbations "
"of epsilon=0.01 (L-infinity norm). Trajectory MSE shall not "
"increase by more than 50% under perturbation.",
"category": "safety",
"verification_method": "analysis",
"traces_to": "STKH-04: Sensor noise must not cause erratic behavior"
},
"REQ-IMPL-01": {
"text": "Single forward pass inference time shall be below 5ms on CPU.",
"category": "implementation",
"verification_method": "demonstration",
"traces_to": "STKH-05: Control loop must run at minimum 100Hz"
},
"REQ-IMPL-02": {
"text": "Model architecture shall match the specification: 2 hidden layers, "
"ReLU activations, input dimension 6, output dimension 13.",
"category": "implementation",
"verification_method": "inspection",
"traces_to": "STKH-06: System shall conform to approved design document"
}
}
Notice the traces_to field in every requirement. This is traceability: each technical requirement links upward to a stakeholder expectation. When a requirement fails verification, you can immediately identify which stakeholder need is at risk.
Notice also the verification_method field. NASA’s four methods (test, analysis, inspection, demonstration) each appear at least once. We are not relying on testing alone.
The verification plan
The verification plan maps each requirement to its method and acceptance criteria. In the notebook, this becomes a structured dictionary that the verification harness consults when running checks:
verification_plan = {
"REQ-PRED-01": {
"method": "test",
"procedure": "Evaluate model on held-out test set. Compute per-timestep "
"MSE and verify each is below threshold.",
"acceptance_criteria": "MSE < 0.05 for all 5 timesteps",
"data_source": "test_dataset (20% holdout, stratified by scenario)"
},
"REQ-SAFE-01": {
"method": "analysis",
"procedure": "Extract all test samples with obstacle_distance < 0.3 and "
"obstacle_angle within [-15, 15] degrees. Verify no "
"'go_straight' predictions in this subset. Additionally, "
"perform bounded input sweep across the critical region.",
"acceptance_criteria": "Zero 'go_straight' outputs in critical region",
"data_source": "test_dataset + synthetic critical-region sweep"
},
# ... similar entries for each requirement
}
Enabling products
The enabling products are the tools and data that make verification possible. In our notebook, these include the test dataset, the trained model checkpoint, a simple kinematic simulator for generating ground truth trajectories, and utility functions for perturbation analysis. We collect them in a dedicated notebook section so they are identifiable and versioned:
enabling_products = {
"test_data": "data/test_trajectories_v1.npz",
"model_checkpoint": "models/trajectory_predictor_v3.pt",
"simulator": KinematicSimulator(dt=0.1, noise_std=0.0),
"perturbation_tool": LinfPerturbation(epsilon=0.01),
"version": "2026-04-08-prep-v1"
}
Activity 2, Performing the verification
With preparation complete, we execute each verification method. The notebook organizes these into clearly labeled sections that correspond to NASA’s four methods.
Verification by test
Test subjects the actual product to controlled stimuli and measures the response. For our trajectory predictor, this means feeding the held-out test set through the network and computing metrics:
def verify_by_test(model, test_loader, requirements):
"""NASA Verification Method: Test.
Subjects the end product to controlled stimuli and measures response."""
results = {}
all_preds, all_targets, all_commands, all_cmd_targets = [], [], [], []
for inputs, traj_targets, cmd_targets in test_loader:
traj_pred, cmd_pred = model(inputs)
all_preds.append(traj_pred)
all_targets.append(traj_targets)
all_commands.append(cmd_pred.argmax(dim=1))
all_cmd_targets.append(cmd_targets)
preds = torch.cat(all_preds)
targets = torch.cat(all_targets)
commands = torch.cat(all_commands)
cmd_targets = torch.cat(all_cmd_targets)
# REQ-PRED-01: Per-timestep MSE
per_step_mse = ((preds - targets) ** 2).mean(dim=0)
results["REQ-PRED-01"] = {
"metric": {f"step_{i}": per_step_mse[i].item() for i in range(5)},
"threshold": 0.05,
"pass": all(m < 0.05 for m in per_step_mse.tolist()),
}
# REQ-PRED-02: Command accuracy
accuracy = (commands == cmd_targets).float().mean().item()
results["REQ-PRED-02"] = {
"metric": {"accuracy": accuracy},
"threshold": 0.92,
"pass": accuracy > 0.92,
}
return results
The function returns structured results, not print statements. Each result ties back to a specific requirement ID. This structure matters because Activity 3 (analysis of outcomes) and Activity 4 (reporting) consume these results programmatically.
Verification by analysis
Analysis uses mathematical models or systematic reasoning to evaluate performance where testing alone is insufficient. For REQ-SAFE-01 (no “go straight” near obstacles), we go beyond the test set by sweeping across the critical input region:
def verify_by_analysis(model, test_data, perturbation_tool):
"""NASA Verification Method: Analysis.
Uses mathematical models and systematic input exploration."""
results = {}
# REQ-SAFE-01: Critical region analysis
# Extract samples where obstacle is close and ahead
critical_mask = (
(test_data["obstacle_distance"] < 0.3) &
(test_data["obstacle_angle"].abs() < np.radians(15))
)
critical_inputs = test_data["inputs"][critical_mask]
# Also generate synthetic sweep across the critical region
sweep_inputs = generate_critical_region_sweep(
obstacle_dist_range=(0.0, 0.3),
obstacle_angle_range=(-15, 15),
n_samples=5000
)
all_critical = torch.cat([critical_inputs, sweep_inputs])
_, cmd_preds = model(all_critical)
go_straight_count = (cmd_preds.argmax(dim=1) == 1).sum().item() # 1 = straight
results["REQ-SAFE-01"] = {
"metric": {
"critical_samples": len(all_critical),
"go_straight_violations": go_straight_count
},
"threshold": 0,
"pass": go_straight_count == 0,
}
# REQ-SAFE-02: Robustness under perturbation
clean_preds, _ = model(test_data["inputs"][:1000])
perturbed_inputs = perturbation_tool.perturb(test_data["inputs"][:1000])
noisy_preds, _ = model(perturbed_inputs)
clean_mse = ((clean_preds - test_data["targets"][:1000]) ** 2).mean().item()
noisy_mse = ((noisy_preds - test_data["targets"][:1000]) ** 2).mean().item()
degradation = (noisy_mse - clean_mse) / clean_mse
results["REQ-SAFE-02"] = {
"metric": {
"clean_mse": clean_mse,
"perturbed_mse": noisy_mse,
"degradation_ratio": degradation
},
"threshold": 0.50,
"pass": degradation < 0.50,
}
return results
The critical region sweep in REQ-SAFE-01 is a form of analysis because we are reasoning systematically about the input space rather than relying on whatever the test set happened to contain. If the test set contained only twelve examples in the critical region, testing alone would offer weak evidence. The synthetic sweep strengthens the argument, and a formal verification tool like auto_LiRPA or alpha-beta-CROWN could strengthen it further by providing certified bounds rather than empirical sampling.
Verification by inspection
Inspection examines the product itself rather than its behavior. For our neural network, this means checking that the architecture, weights, and configuration match the approved design:
def verify_by_inspection(model, spec):
"""NASA Verification Method: Inspection.
Examines the product for conformance to specification."""
results = {}
# REQ-IMPL-02: Architecture conformance
checks = {
"input_dim": model.layers[0].in_features == spec["input_dim"],
"output_dim": model.layers[-1].out_features == spec["output_dim"],
"num_hidden": len([l for l in model.layers if isinstance(l, nn.Linear)]) - 1
== spec["num_hidden_layers"],
"activation": all(
isinstance(model.layers[i], nn.ReLU)
for i in range(1, len(model.layers) - 1, 2)
),
}
results["REQ-IMPL-02"] = {
"metric": checks,
"pass": all(checks.values()),
}
return results
This might seem trivial, but inspection catches a class of errors that testing never will. If someone swaps a ReLU for a Sigmoid during a refactoring, the model might still pass accuracy tests while violating the design specification in ways that affect formal verification guarantees (since Reluplex and CROWN are specific to piecewise-linear networks).
Verification by demonstration
Demonstration shows that the product performs its required functions under realistic conditions. For latency requirements, this means measuring actual inference time rather than computing theoretical FLOPs:
def verify_by_demonstration(model, sample_input, n_trials=1000):
"""NASA Verification Method: Demonstration.
Shows required functions are performed under realistic conditions."""
results = {}
# REQ-IMPL-01: Inference latency
times = []
for _ in range(n_trials):
start = time.perf_counter()
with torch.no_grad():
_ = model(sample_input)
elapsed = (time.perf_counter() - start) * 1000 # ms
times.append(elapsed)
p50 = np.percentile(times, 50)
p99 = np.percentile(times, 99)
results["REQ-IMPL-01"] = {
"metric": {"p50_ms": p50, "p99_ms": p99, "max_ms": max(times)},
"threshold": 5.0,
"pass": p99 < 5.0,
}
return results
We use the 99th percentile rather than the mean because a control loop that meets latency requirements on average but occasionally spikes to 50ms is not meeting the stakeholder need for consistent 100Hz operation. This distinction between average-case and worst-case thinking is one of the places where systems engineering discipline most directly helps AI development.
Activity 3, Analyzing the outcomes
Running verification methods produces raw results. Activity 3 turns those results into a verdict by checking each result against its acceptance criteria and identifying any failures that require action.
In the notebook, this is a function that consumes all verification outputs, applies the acceptance criteria from the verification plan, and produces a structured assessment:
def analyze_verification_outcomes(all_results, requirements, verification_plan):
"""NASA Activity 3: Analyze the outcomes of product verification."""
assessment = {}
for req_id, req in requirements.items():
result = all_results.get(req_id)
if result is None:
assessment[req_id] = {
"status": "NOT EXECUTED",
"requirement": req["text"],
"traces_to": req["traces_to"],
"action_required": "Verification not performed. Investigate."
}
elif result["pass"]:
assessment[req_id] = {
"status": "PASS",
"requirement": req["text"],
"traces_to": req["traces_to"],
"evidence": result["metric"],
}
else:
assessment[req_id] = {
"status": "FAIL",
"requirement": req["text"],
"traces_to": req["traces_to"],
"evidence": result["metric"],
"action_required": (
f"Requirement not met. Threshold: {result.get('threshold')}. "
f"Review design and consider corrective action."
)
}
return assessment
When a requirement fails, the assessment includes which stakeholder expectation is affected (through traces_to) and flags that corrective action is needed. This is where the traceability infrastructure pays off. A failing REQ-SAFE-01 doesn’t just mean “a test failed” but specifically means “STKH-03 (Robot must not collide with detected obstacles) is at risk.”
Activity 4, Preparing the verification report
NASA requires a formal report, not scattered Jupyter cell outputs. In the notebook, we generate a structured summary that can be exported or reviewed:
def prepare_verification_report(assessment, metadata):
"""NASA Activity 4: Prepare a product verification report."""
report = {
"title": "Product Verification Report",
"system": metadata["system_name"],
"model_version": metadata["model_version"],
"date": metadata["date"],
"prepared_by": metadata["prepared_by"],
"summary": {
"total_requirements": len(assessment),
"passed": sum(1 for a in assessment.values() if a["status"] == "PASS"),
"failed": sum(1 for a in assessment.values() if a["status"] == "FAIL"),
"not_executed": sum(
1 for a in assessment.values() if a["status"] == "NOT EXECUTED"
),
},
"details": assessment,
"disposition": "",
}
if report["summary"]["failed"] > 0:
report["disposition"] = (
"CONDITIONAL: System has open verification failures. "
"Do not proceed to validation until failures are resolved."
)
elif report["summary"]["not_executed"] > 0:
report["disposition"] = (
"INCOMPLETE: Some requirements have not been verified. "
"Complete all verification activities before proceeding."
)
else:
report["disposition"] = (
"VERIFIED: All requirements have been verified successfully. "
"System may proceed to product validation."
)
return report
The disposition field is important. In NASA’s process, a verified end product flows to the Product Validation Process (the top-right output in Figure 5.3-1). But if verification is incomplete or has failures, the system does not advance. The notebook enforces this gate programmatically, and printing the disposition in a clearly formatted cell gives reviewers an unambiguous status.
Activity 5, Capturing work products
The final activity preserves all artifacts for the Technical Data Management Process. In practice this means saving the report, the raw results, the model checkpoint, the test data, and the verification code itself in a versioned, reproducible bundle:
def capture_work_products(report, all_results, enabling_products, output_dir):
"""NASA Activity 5: Capture the work products from product verification."""
os.makedirs(output_dir, exist_ok=True)
# Save the report
with open(os.path.join(output_dir, "verification_report.json"), "w") as f:
json.dump(report, f, indent=2, default=str)
# Save raw results
with open(os.path.join(output_dir, "raw_results.json"), "w") as f:
json.dump(all_results, f, indent=2, default=str)
# Copy model checkpoint
shutil.copy(
enabling_products["model_checkpoint"],
os.path.join(output_dir, "verified_model.pt")
)
# Record environment
with open(os.path.join(output_dir, "environment.txt"), "w") as f:
f.write(f"Python: {sys.version}\n")
f.write(f"PyTorch: {torch.__version__}\n")
f.write(f"NumPy: {np.__version__}\n")
f.write(f"Date: {datetime.now().isoformat()}\n")
return output_dir
This step is the one most AI practitioners skip entirely. Without it, you cannot reproduce the verification, audit the results, or compare across model versions. NASA requires it because when something fails in space, the investigation starts by pulling the verification records. When an AI system fails in production, you want the same capability.
What the notebook looks like end to end
The full notebook follows this sequence: a header cell with metadata (system name, version, date, author), then the five activities as clearly labeled sections. The final cell prints the disposition and a summary table:
============================================
PRODUCT VERIFICATION REPORT
System: Robot Trajectory Predictor v3
Date: 2026-04-08
============================================
REQ-PRED-01 [PASS] Trajectory MSE: 0.032 (threshold: 0.05)
REQ-PRED-02 [PASS] Command accuracy: 94.3% (threshold: 92%)
REQ-SAFE-01 [FAIL] 3 violations in 5847 critical samples
REQ-SAFE-02 [PASS] Degradation: 31.2% (threshold: 50%)
REQ-IMPL-01 [PASS] P99 latency: 1.8ms (threshold: 5ms)
REQ-IMPL-02 [PASS] Architecture conforms to specification
DISPOSITION: CONDITIONAL
System has open verification failures.
Do not proceed to validation until failures are resolved.
Failed requirements trace to:
- STKH-03: Robot must not collide with detected obstacles
============================================
This example output shows a realistic scenario where the model passes five of six requirements but fails the critical safety requirement REQ-SAFE-01, with three cases where it predicted “go straight” in the obstacle danger zone. The disposition is CONDITIONAL: the system cannot advance to validation until this is resolved. The traceability immediately tells us which stakeholder need is at risk.
The next step, which is outside the scope of this post, would be to investigate those three violations, determine whether the training data underrepresented the critical region, retrain or fine-tune, and re-run verification. The NASA process is iterative by design.
Why this matters beyond the notebook
The verification infrastructure we built, requirements with traceability, four distinct methods, structured reporting, work product capture, is roughly 150 lines of Python. The model itself is maybe 30 lines. The ratio tells you something about where the real engineering effort belongs.
This pattern scales. For a more complex system like a demand forecasting LSTM or an autonomous vehicle perception stack, the requirements grow and the verification methods become more sophisticated (replacing our perturbation sweep with certified bounds from alpha-beta-CROWN, for example), but the five-activity structure remains the same.
The notebook format has a specific advantage here. Unlike a separate test suite that runs in CI/CD and produces logs that nobody reads, a Jupyter notebook combines the verification code, the results, and the narrative explanation in a single artifact. When a reviewer opens the notebook, they see not just “PASS” or “FAIL” but the reasoning, the data, the acceptance criteria, and the traceability, all in one place. It’s a verification report that is also executable.
For organizations in the Gulf region building AI systems under Saudi Arabia’s emerging autonomous vehicle regulations or GACA’s aviation framework, this kind of structured verification evidence is becoming a practical necessity rather than an academic exercise.
Try it yourself
We will release the complete notebook on the AI V and V Lab resources page. The notebook includes the kinematic simulator, data generation, model training, and the full five-activity verification harness. You can swap in your own model and requirements, and the verification infrastructure adapts.
If you’ve read our earlier post on what systems engineers know, consider this the homework assignment. The concepts in that post become code in this one.