Can We Verify LLM Safety Through Hidden-State Geometry

A prompt injection attack works by overriding a language model’s behavioral specification with adversarial instructions embedded in the user input. The model processes both the safety prompt and the attack prompt as a single token stream, and when the attack wins, the output violates the intended constraints. We wanted to understand what this conflict looks like inside the model, so we built a small experiment and then went looking for what the research community has found.
The experiment is straightforward. We took a GPT-2 architecture, defined a safety specification (a system-prompt-style guardrail restricting the model to cooking-related topics), and ran three types of prompts through it: an original query with no safeguard, the same query wrapped in the safeguard, and five different prompt injection attacks that attempt to break the safeguard. For each prompt, we extracted the last-layer hidden states across 40 generated tokens and computed a single centroid vector representing that prompt’s position in the model’s 256-dimensional representation space.
We then built a t-SNE density map from background safe and attack samples and plotted each prompt’s centroid on top of it. The result is the figure below.
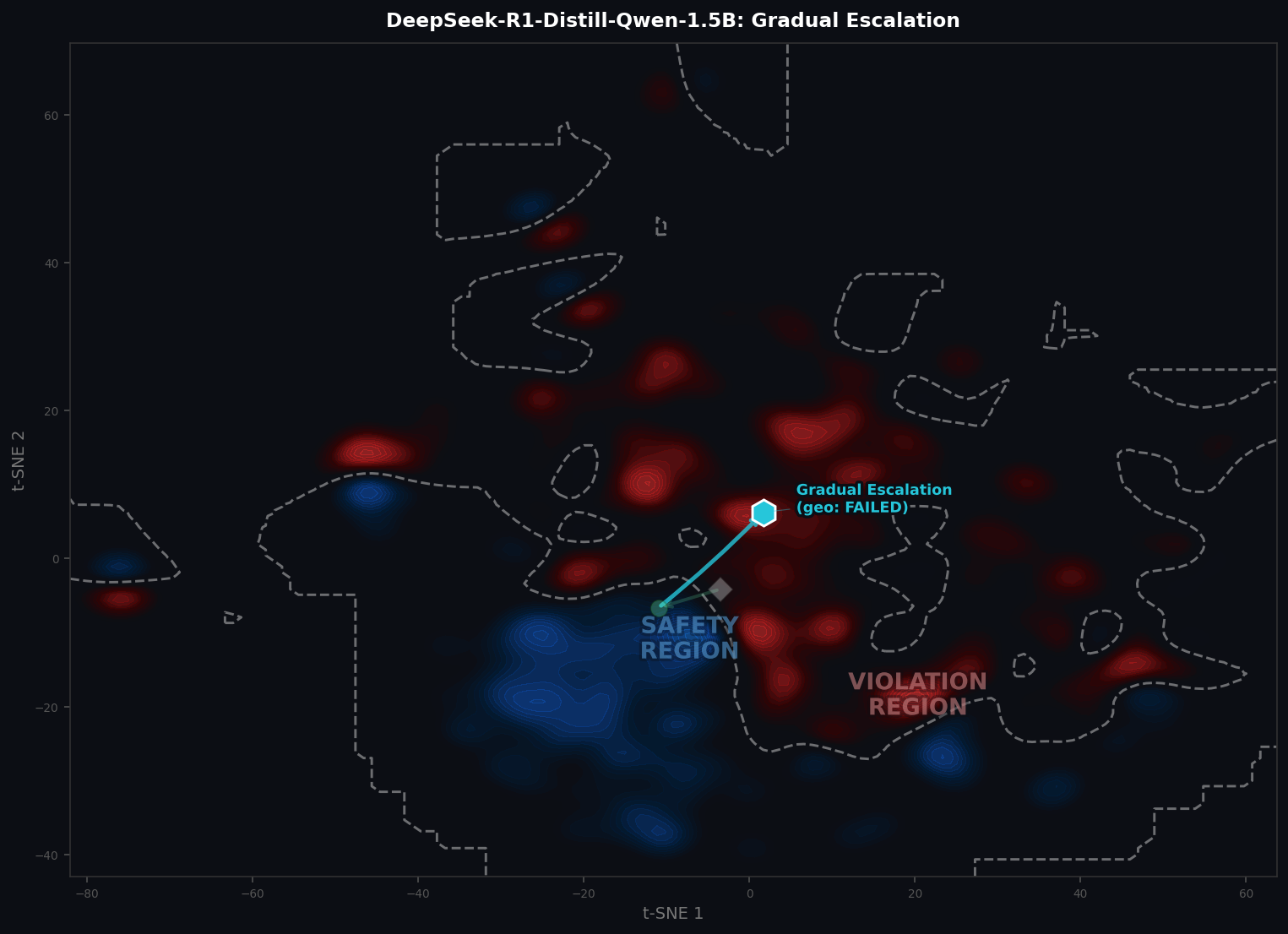 The safeguard creates a directional pull (green arrow) in hidden-state space. Each attack creates a counter-pull. When the attack nudge overcomes the safeguard direction, the prompt’s centroid escapes into the violation region (red zone) and the safeguard fails.
The safeguard creates a directional pull (green arrow) in hidden-state space. Each attack creates a counter-pull. When the attack nudge overcomes the safeguard direction, the prompt’s centroid escapes into the violation region (red zone) and the safeguard fails.
The geometry tells a clean story. The safeguard specification shifts the model’s representations from the unconstrained Original position toward the safety region (the blue-dominant density zone). Each attack creates a counter-force that nudges the output in a different direction. Attacks whose centroids land in the blue zone are cases where the safeguard held. Attacks whose centroids escape into the red zone are cases where the safeguard failed, meaning the attack’s directional nudge was stronger than the safeguard’s pull.
This raises the obvious question: is hidden-state geometry a viable approach for verifying LLM safety at scale?
What the research says
The short answer is that the geometric intuition is well-supported by recent literature, but the specific approach matters enormously. The field has moved well beyond simple t-SNE visualizations into precise characterizations of how safety information is structured in the latent space.
The foundational result is from Arditi et al. (2024), who showed that refusal in language models is mediated by a single direction in the activation space. Ablating that direction from the model’s weights jailbreaks it without degrading general utility, and steering along it strengthens the model’s refusal even for benign prompts. This is remarkable because it means the safeguard’s effect on our t-SNE plot isn’t just a statistical tendency across many dimensions but is concentrated along a specific, recoverable vector.
Zhou et al. (2024) extended this with their EMNLP Findings paper “How Alignment and Jailbreak Work”, which is the closest published work to our notebook experiment. They trained weak classifiers on intermediate hidden states across five model families (Llama 2, Llama 3, Vicuna, Mistral, and Falcon) from 7B to 70B parameters. Their key finding is that LLMs learn ethical concepts during pre-training, not during alignment, and can distinguish malicious from normal inputs in the early layers. Alignment then associates these early ethical classifications with emotional responses in the middle layers and refines them into specific refusal tokens in the final layers. Jailbreak attacks work by disrupting the middle-layer transformation from ethical classification into negative emotion, which is a more specific version of the “attack nudge overcomes safeguard pull” story our density map illustrates.
Zhao et al. (2025) at NeurIPS took this further by showing that LLMs encode harmfulness and refusal separately, at different token positions. Harmfulness is encoded at the last token of the user instruction, while refusal is encoded at the last token of the full sequence. This matters for verification because it means monitoring a single layer or a single token position misses half the picture.
The broader framework that connects all of this work is Representation Engineering (Zou et al., ICLR 2024), which treats safety-relevant concepts as linear directions in the activation space that can be read, steered, and monitored. A curated collection of papers in this area is maintained at the Awesome Representation Engineering repository.
From visualization to verification
Our t-SNE density map is a pedagogical tool, not a production verification system. The research literature reveals several gaps between what we built and what would be needed for real V&V.
The first gap is dimensionality. We collapsed 40 token-level hidden states into a single centroid and projected everything to 2D. The actual safety-relevant structure lives in specific directions within the full-dimensional space, and those directions are recoverable with simple linear probes. A 2025 ICML paper on “The Hidden Dimensions of LLM Alignment” showed that the safety residual space (the subspace spanned by representation shifts during safety fine-tuning) is approximately low-rank and can be decomposed into orthogonal feature directions with distinct semantic meanings. Multiple orthogonal directions predict refusal behavior beyond the single dominant direction, which means the safety subspace is richer than a single vector but still tractable for automated monitoring.
The second gap is layer specificity. Our notebook uses only the final layer, but Zhou et al. showed that the model processes safety information progressively across layers. The LARF pipeline (EMNLP 2025) operationalizes this by identifying the most safety-sensitive layer through a scaling analysis, then computing safe and unsafe reference representations at that specific layer to score new inputs. HiddenDetect (2025) captures hidden states at the final token position of each layer, projects them into vocabulary space, and computes refusal-related semantics across layers, which is closer to a practical runtime monitor.
The third gap is adversarial robustness. The most sobering result comes from Nasr et al. (October 2025), a joint study by researchers across OpenAI, Anthropic, and Google DeepMind titled “The Attacker Moves Second.” They tested twelve published defenses using adaptive attack methods (gradient descent, reinforcement learning, random search, and human red teaming), and the majority of those defenses, which originally reported near-zero attack success rates, were bypassed at 90%+ success rates under adaptive conditions. Prompting-based defenses collapsed to 95-99% attack success. This means that any hidden-state monitoring system would itself become a target for adversarial optimization, and its geometric decision boundary could be evaded by attacks specifically crafted to land in the safe region while still producing harmful outputs.
What we recommend reading
For researchers and practitioners who want to go deeper, we recommend the following papers and their associated code, organized by what question they answer.
How does safety live in the representation space? The Representation Engineering survey (2025) covers the full landscape of how probes, steering vectors, and activation engineering relate to LLM safety. The Awesome LLM Interpretability repository maintains a continuously updated list of papers on mechanistic interpretability with a strong section on safety-related work. For a comprehensive list of safety papers specifically, see the Awesome LLM Safety Papers repository.
Can we detect attacks at inference time? Zheng et al.’s “On Prompt-Driven Safeguarding for Large Language Models” (ICML 2024) provides a solid experimental framework with code for analyzing how prompt-based safeguards work in representation space. The “SafeSteer” paper (2025) proposes category-wise inference-time steering via activation engineering, using a single forward pass to deflect harmful prompts by steering activations from unsafe regions to safe non-refusal regions.
What about runtime enforcement with formal specifications? The “AgentSpec” framework (ICSE 2026) takes a different but complementary approach, using customizable formal specifications for runtime enforcement of LLM agent behavior rather than relying on hidden-state geometry.
Where this fits in our research
The hidden-state geometry approach connects directly to the verification methods we use in our lab’s work on neural network V&V. The density-based decision boundary in the t-SNE plot is the empirical analog of the certified bounds computed by tools like auto_LiRPA for feedforward networks. In the generative LLM setting, the “perturbation” is textual (a prompt injection) rather than numerical (an epsilon-ball), but the verification question is the same: does the output remain within the specification envelope under adversarial input?
The notebook we built is available in our repository and runs end-to-end on a CPU. We encourage practitioners to reproduce the experiment with pretrained GPT-2 weights (a two-line change documented in the notebook) to see how the semantic content of safe vs. attack outputs produces even sharper separation in the hidden-state projections.
The geometric framing is sound. The safeguard is a directional force in representation space, and each attack is a counter-force. When the counter-force wins, the output crosses the decision boundary. The open challenge, and the focus of ongoing work both in our lab and across the community, is building monitoring systems robust enough that the boundary itself doesn’t become the next attack surface.
References
- Arditi et al. (2024). “Refusal in Language Models Is Mediated by a Single Direction.” GitHub
- Zhou et al. (2024). “How Alignment and Jailbreak Work: Explain LLM Safety through Intermediate Hidden States.” EMNLP 2024 Findings. GitHub · Paper
- Zhao et al. (2025). “LLMs Encode Harmfulness and Refusal Separately.” NeurIPS 2025. GitHub
- Zou et al. (2024). “Representation Engineering: A Top-Down Approach to AI Transparency.” ICLR 2024. GitHub
- Zheng et al. (2024). “On Prompt-Driven Safeguarding for Large Language Models.” ICML 2024. GitHub
- “The Hidden Dimensions of LLM Alignment: A Multi-Dimensional Safety Analysis.” ICML 2025. Paper
- Nasr et al. (2025). “The Attacker Moves Second: Stronger Adaptive Attacks Bypass Defenses Against LLM Jailbreaks and Prompt Injections.” Paper
- “Representation Engineering for Large-Language Models: Survey and Research Challenges.” CSUR 2025. Paper
- Awesome Representation Engineering — Curated paper list
- Awesome LLM Interpretability — Interpretability papers and tools
- Awesome LLM Safety Papers — Comprehensive safety paper list