What the AI Index 2026 Tells Us About the Gap Between AI Capability and AI Assurance

The ninth edition of Stanford HAI’s AI Index Report landed this month, and its Chapter 3 on Responsible AI is the most important 45 pages the field has published this year. The chapter does not argue about whether modern AI is impressive. That argument is over. It asks a harder question, which is whether the infrastructure around these systems is keeping up with what they can now do, and the answer is a careful and well-documented no.
For those of us working on AI verification, validation, and certification, the chapter reads less like a report and more like a situation map. It shows exactly where the measurement gaps sit, where policy is moving, where industry practice is hardening, and where the tradeoffs between responsible AI dimensions remain unresolved. This post walks through what we found most significant, with direct implications for the research we are doing at the AI V&V Lab.
 Figure 1. Chapter 3 Highlights from the AI Index Report 2026. Eight findings that together describe a field scaling faster than its assurance infrastructure.
Figure 1. Chapter 3 Highlights from the AI Index Report 2026. Eight findings that together describe a field scaling faster than its assurance infrastructure.
The headline number that should reshape procurement decisions
The AI Incident Database recorded 362 documented AI incidents in 2025, up from 233 the previous year. Annual incident counts had stayed below 100 until 2022. The OECD’s automated monitor, which uses a multilingual pipeline across news sources, recorded a monthly peak of 435 in January 2026 with a six-month moving average of 326. Both databases track incidents differently, and both show the same direction of travel.
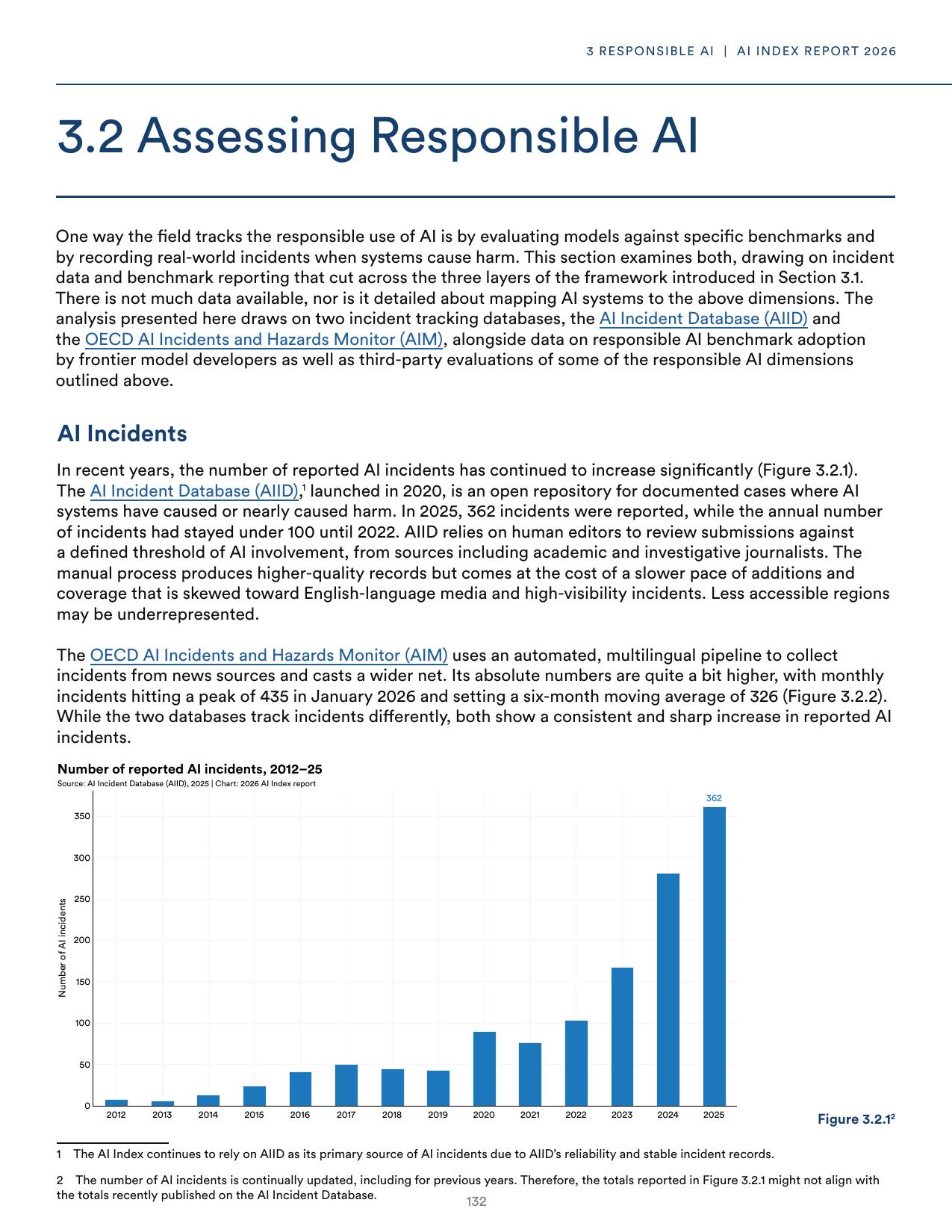 Figure 2. Documented AI incidents tracked by the AI Incident Database. Figure 3.2.1 from the AI Index Report 2026. The 362 incidents logged in 2025 underrepresent the true total, since the AIID relies on human editors and English-language media.
Figure 2. Documented AI incidents tracked by the AI Incident Database. Figure 3.2.1 from the AI Index Report 2026. The 362 incidents logged in 2025 underrepresent the true total, since the AIID relies on human editors and English-language media.
Anyone arguing that AI deployment should slow down to match the pace of governance has lost that argument already. Adoption is not slowing. Organizational uptake reached 88% in 2025, and generative AI hit 53% population-level adoption within three years of mass-market release. The question is no longer whether to deploy. It is how to deploy responsibly, and what assurance evidence should be required before a system enters service in a regulated domain.
This is the gap the AI Index documents across eight dimensions, and it is the gap our lab was set up to help close.
The benchmarking asymmetry
One of the most useful observations in the chapter is about what frontier labs choose to report. Almost every frontier model developer reports capability numbers on MMLU, GPQA, AIME, and SWE-bench Verified. These have become the shared vocabulary of model releases. On responsible AI benchmarks such as BBQ for fairness, HarmBench and StrongREJECT for security, SimpleQA for factuality, and MakeMePay for autonomy, the reporting table in the Index is mostly empty. Only Claude Opus 4.5 reports results on more than two of these benchmarks, and only GPT-5.2 reports StrongREJECT.
This does not mean frontier labs are ignoring responsible AI. They run extensive internal red-teaming and alignment testing. It means that the results of those efforts rarely translate into a common, externally comparable set of numbers that a procurement officer, regulator, or systems integrator can use to compare systems head-to-head. In systems engineering terms, there is no standardized verification evidence package. In the NASA Systems Engineering Handbook framework we discussed in an earlier post, this is the difference between an activity that produced internal confidence and a verification report that flows into an acceptance decision.
The Index also flags a second asymmetry, which is that foundation model transparency dropped in 2025. After rising on the Foundation Model Transparency Index from an average score of 37 in 2023 to 58 in 2024, the 2025 average fell back to 40. Major gaps persist in disclosure around training data, compute resources, and post-deployment impact. The systems getting the most capable are getting less observable at exactly the moment when observability matters more.
The safety ceiling that isn’t
HELM Safety results show most 2024 to 2025 models scoring between 0.90 and 0.98 on the mean safety score, with the gap between the best and worst leading models narrower than it has ever been. Taken alone, this looks like good news. Leading systems are converging on a safety ceiling.
The AILuminate jailbreak benchmark, reported in the same chapter, tells a different story about what that safety score actually certifies.
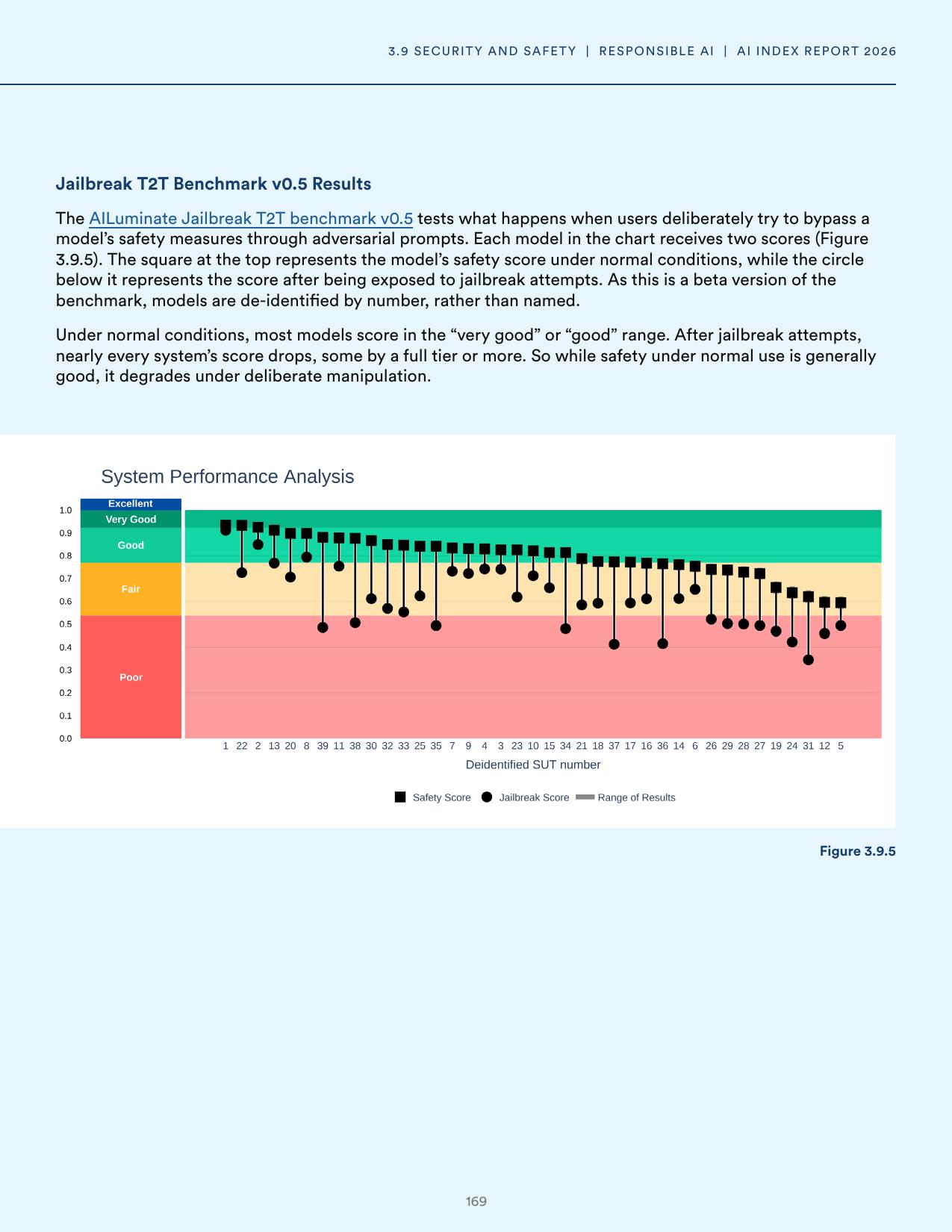 Figure 3. Figure 3.9.5 from the AI Index Report 2026. The square marks each model’s safety score under normal conditions. The circle marks the same model’s score after adversarial prompts. Most models lose a full rating tier or more.
Figure 3. Figure 3.9.5 from the AI Index Report 2026. The square marks each model’s safety score under normal conditions. The circle marks the same model’s score after adversarial prompts. Most models lose a full rating tier or more.
Nearly every model tested drops from very good or good into fair or poor once adversarial prompts enter the picture. A safety score that collapses under deliberate manipulation is exactly the kind of brittle property that classical testing cannot fully certify, because the adversary gets to choose the inputs after the test suite is fixed. This is the reason formal verification and certified robustness have moved from a niche topic into a central research direction at our lab.
Our ongoing work on applying α,β-CROWN and auto_LiRPA to supply chain regression tasks is a direct response to this observation. If you cannot bound a model’s behavior over an entire input neighborhood, you cannot make a defensible claim that the model is safe, only that it passed the tests you happened to run. Certified robustness gives you a mathematical guarantee over a region, which is a fundamentally different epistemic object than a benchmark score.
Knowledge versus belief, and why it matters for clinical and legal AI
Among the newer benchmarks in the chapter, KaBLE deserves particular attention. It tests whether language models can distinguish between what is known and what is merely believed. Across 24 leading models, accuracy drops sharply when a false statement is framed as something the user believes rather than something a third party believes. GPT-4o falls from 98.2% on true-belief tasks to 64.4% on first-person false beliefs. DeepSeek R1 falls from over 90% to 14.4%.
For anyone building AI into regulated decision-support workflows, this is not an abstract curiosity. A clinical decision-support system that cannot separate a patient’s mistaken belief from established medical fact can reinforce a wrong diagnosis. A legal summarization tool that conflates what a witness believes with what is known can misrepresent evidence. These are exactly the verification questions that matter for the standards cited later in the chapter, particularly the NIST AI Risk Management Framework’s validity and reliability dimension.
The standards landscape has hardened
The most consequential shift in the 2025 industry data is the arrival of two new regulatory influences on organizational responsible AI practice. ISO/IEC 42001, the AI management system standard, was cited by 36% of organizations in the McKinsey survey that backs the chapter. The NIST AI Risk Management Framework was cited by 33%. Neither standard appeared in the 2024 edition of the same survey.
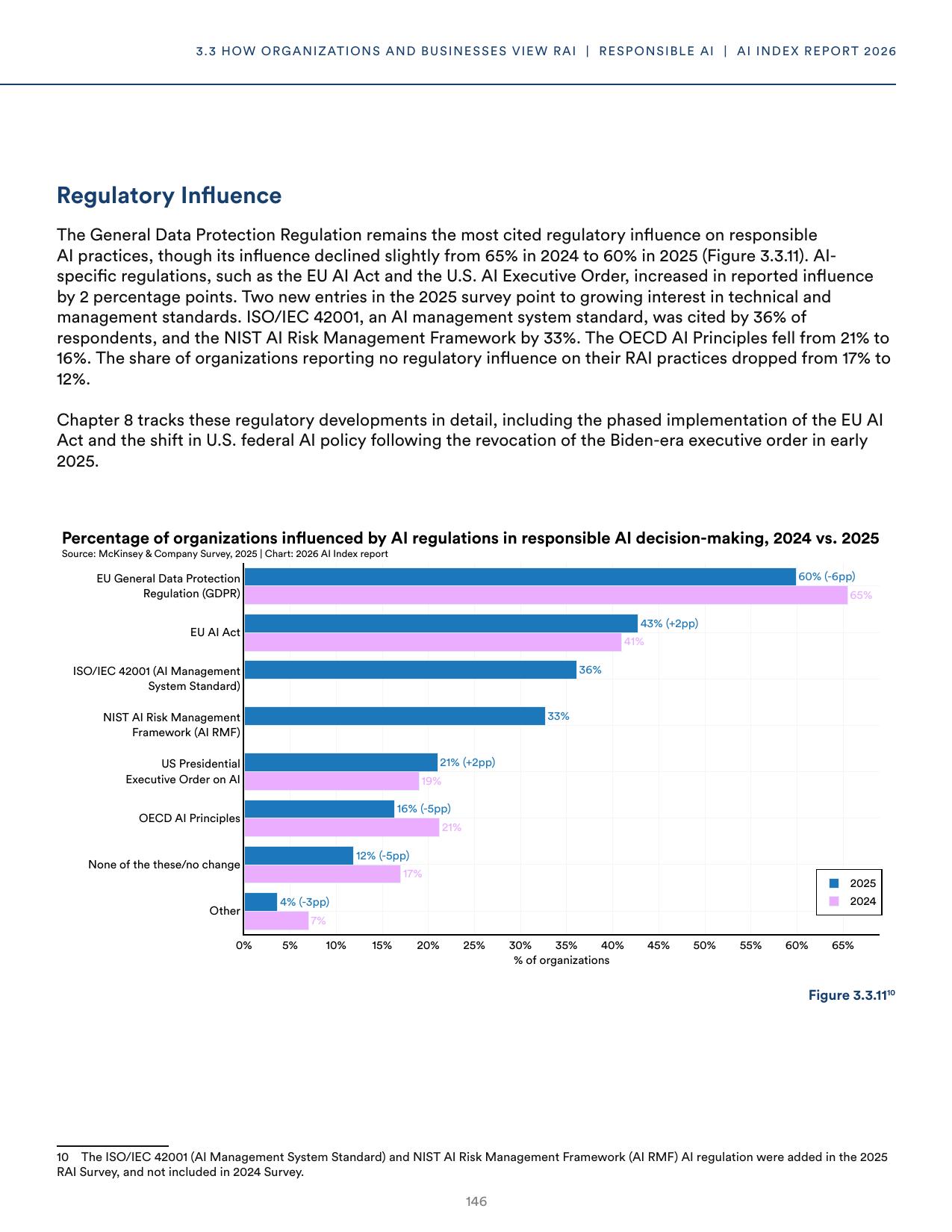 Figure 4. Figure 3.3.11 from the AI Index Report 2026. The share of organizations reporting no regulatory influence at all dropped from 17% to 12% in one year, while ISO/IEC 42001 and NIST AI RMF entered the landscape as major reference points.
Figure 4. Figure 3.3.11 from the AI Index Report 2026. The share of organizations reporting no regulatory influence at all dropped from 17% to 12% in one year, while ISO/IEC 42001 and NIST AI RMF entered the landscape as major reference points.
GDPR remains the most cited influence at 60%, and the EU AI Act rose to 43% as its first prohibitions took effect. The trajectory matters more than any single number. One year ago, there was a reasonable argument that AI-specific standards were aspirational documents without real traction. That argument is harder to make now. Technical and management standards are starting to shape procurement language, vendor assessment, and internal governance in measurable ways.
For research labs, this creates a concrete translation problem. The dimensions in NIST AI RMF and ISO/IEC 42001 have to map onto evaluation protocols that produce evidence. That mapping is where systems engineering becomes genuinely useful. The V model, requirements traceability, verification methods, and structured test reports were built for exactly this kind of translation between policy-level requirements and technical acceptance criteria.
Our AI V&V notebook for the NASA Product Verification Process is one attempt at this translation, showing what a structured verification report looks like when you treat an AI component as a system element with requirements, methods, activities, and dispositions rather than as a magic box that either works or does not.
The tradeoff problem that nobody has solved
Section 3.10 of the AI Index may be the most important part of the chapter for researchers. It reports on a growing body of empirical work showing that responsible AI dimensions do not improve independently, and that optimizing for one dimension typically degrades others.
Kemmerzell and Schreiner trained image classifiers with differential privacy, fairness adaptations, and robustness-focused data augmentation across four facial-analysis datasets. Differential privacy improved privacy scores consistently, and it reduced accuracy by up to 33 percentage points on some configurations while also cutting explainability and fairness. Training aimed at improving fairness only succeeded on the dataset with the most demographic imbalance. Across 11 large language models, Cecchini and colleagues found that models leading on robustness tended to score lowest on toxicity avoidance, with Mistral 7B and Mixtral 8x7B ranking near the bottom on the toxicity dimension where GPT-4 ranked near the top.
In a federated-learning study on Alzheimer’s MRI scans, adding stronger differential privacy protection dropped diagnostic accuracy by 14.8 percentage points, with missed diagnoses rising by 21.4% at hospitals with less data. Encryption-based alternatives preserved fairness but required two to three times more compute.
The Index is blunt about what this means. There is no shared framework for measuring or comparing these tradeoffs, and without one, the field cannot tell whether it is getting better at managing them. For certification, this is the central unsolved problem. An assurance case that claims a system is safe, fair, private, accurate, and robust needs to address the interactions between those properties, not just their individual scores. That is the frontier of responsible AI research right now, and it is where we see the clearest role for systems engineering methods that were designed from the beginning to handle multi-objective tradeoffs with explicit reasoning about acceptable residual risk.
What this means for the work ahead
Three threads from Chapter 3 map directly onto the research agenda at our lab.
The first is the translation of NIST AI RMF and ISO/IEC 42001 dimensions into structured verification protocols that produce evidence suitable for third-party review. We have been building this out through the NASA Systems Engineering Handbook lens, because the handbook already encodes decades of hard-won experience about how to turn abstract quality goals into acceptable test reports. The gap between what the Index calls “internal evaluation” and what it calls “externally comparable benchmarks” is exactly the gap that structured V&V was designed to close.
The second is certified robustness for practical AI workloads. The AILuminate jailbreak data is only the most public example of safety scores that hold under nominal conditions and collapse under adversarial ones. Our work applying α,β-CROWN and auto_LiRPA to LSTM-based demand forecasting and newsvendor deep-network verification is an attempt to show that certified guarantees are reachable for operational research problems that real supply chains care about. The novelty sits in the regression setting, where most neural network verification tooling has focused on classification.
The third is the honest accounting of tradeoffs. We agree with the Index that improving one responsible AI dimension at the expense of another, without saying so clearly, is its own kind of failure. Structured reporting that names the tradeoffs, documents the verification evidence for each dimension, and flags the residual concerns is more useful to a procurement officer or a regulator than a single glossy score. This is the pattern our published verification reports are designed to follow.
A field that is measurable, and a field that is not
The AI Index team ends the chapter with a careful observation about measurement gaps. Fairness, privacy, and explainability lack the standardized data needed to track progress over time, and this measurement gap limits what the chapter itself can say. We would add a closely related observation. The responsible AI community is very good at producing benchmarks, and much less good at producing verification evidence that matches the standards communities are starting to adopt.
The translation problem is where our lab does its work. It sits between the world of AI research, where new benchmarks appear every month, and the world of certification, where an evaluator needs to be able to read a report, follow the traceability, reproduce the method, and make a defensible acceptance decision. Closing that gap is slower work than publishing a new benchmark. The 362 incidents in 2025 suggest that it is also the work the field most urgently needs.